들어가면서..
Maru-egg (입시 정보 안내 RAG 챗봇) 프로젝트를 실제 운영 환경에 배포하면서 모니터링 시스템 구축에 대한 필요성을 느끼게 되었습니다. 학교 입학 홈페이지가 공개되고 실제 입시생들이 사용하기 시작하면서, 예상치 못한 트래픽과 시스템 부하에 어떻게 대응할지 고민하게 되었습니다.
처음에는 단순히 서버가 잘 돌아가는지 확인하는 정도로만 생각했지만, 실제 사용자들이 늘어나면서 서버의 상태를 실시간으로 파악하고 잠재적인 성능 병목이나 오류를 조기에 발견하는 것이 얼마나 중요한지 깨닫게 되었습니다.
이에 Prometheus를 활용해 메트릭을 수집하고, Loki와 Promtail로 로그를 집계한 다음, Grafana를 통해 이를 시각화하는 모니터링 환경을 구축했습니다.
특히 CPU 사용률, DB Connection Pools, HTTP 네트워크 상태를 중점적으로 모니터링하며, 임계값을 설정하여 특정 상황에서 Discord로 알림이 가도록 구성했으며, 특정 로그에 대해 별도로 수집해서 운영에 용이하도록 구성했습니다.
또한 처음엔 프로덕트 서버에 함께 모니터링 시스템을 두었지만, 모니터링 서버가 프로덕트 서버와 독립되어야 모니터링의 필요 시점에 정상 작동할 수 있다는 것을 깨닫고 분리하기도 했습니다.
이 과정에서 모니터링 데이터를 바탕으로 "DB Connection 점유 줄이기: OSIV와 단계적 CQRS 그리고 트랜잭션 설계" 같은 글을 작성하게 되었고, 모니터링을 통해 얻은 인사이트를 실제 성능 개선으로 연결하는 경험을 하게 되었습니다.
이 글에서는 제가 Maru-egg 프로젝트에서 구축한 모니터링 시스템과 수집된 데이터를 바탕으로 어떻게 성능 최적화 포인트를 찾고 개선하고자 했는지, 공부했던 내용과 그 경험을 공유하고자 합니다.
목차
- 사용된 Grafana 템플릿
- 모니터링 지표와 그 의미
- 모니터링 시점과 해석 & 조치
- 적용한 로그 최적화 전략
- 통합 분석 전략 (상관관계, 추세)
- 마무리 및 reference
저 또한 공부하면서 기록하고 정리한 내용이고, 각 환경에 따라 필요한 조치는 달라지기 때문에 참고용으로만 봐주시길 바랍니다!
사용된 Grafana 템플릿
- ID:19004
더 많은 템플릿은 아래의 링크에서 확인할 수 있습니다.
https://grafana.com/grafana/dashboards/

모니터링 지표와 그 의미
우선 각 지표가 의미하는 부분을 정리해보겠습니다.
시스템 가용성 지표

Uptime/Start time
- Uptime: 서버가 얼마나 오래 동작했는지 나타내는 지표로, 갑작스러운 감소는 예기치 않은 재시작을 의미합니다.
- Start time: 서버의 마지막 시작 시간으로, 변경 사항은 시스템 재시작이 있었음을 알려줍니다.
중요성: 안정적인 서비스 운영을 위한 기본 지표로, 재시작 빈도가 높다면 근본적인 안정성 문제가 있을 수 있습니다.
리소스 사용 지표
CPU Usage & Load Average
- CPU 사용률: 프로세스가 CPU를 얼마나 사용하는지 나타내며, 70% 이상은 높은 부하 상태입니다.
- Load Average: 시스템 전체의 부하를 나타내는 지표로, CPU 코어 수보다 높으면 과부하 상태입니다.
중요성: CPU 리소스 부족은 응답 시간 지연과 처리량 감소의 직접적인 원인이 됩니다.
Process Open Files
- 파일 핸들 수: 프로세스가 열어둔 파일/소켓의 수로, 지속적 증가는 리소스 누수를 의미합니다.
중요성: 파일 핸들 한계에 도달하면 새로운 연결을 맺지 못해 서비스 불능 상태가 될 수 있습니다.
메모리 관리 지표

Heap/Non-Heap Memory
- Heap: 자바 객체가 저장되는 공간으로, 사용률이 지속적으로 증가하면 메모리 누수를 의심해볼 수 있습니다.
- Non-Heap: 클래스 메타데이터, 코드 캐시 등이 저장되는 공간으로, 동적 클래스 로딩이 많은 환경에서 중요합니다.
중요성: 메모리 부족은 애플리케이션 성능 저하와 `OutOfMemoryError`의 주요 원인입니다.
JVM 세대별 메모리 (Eden, Survivor, Old Gen)
- Eden Space: 새로 생성된 객체가 저장되는 공간으로, 톱니 모양 패턴은 객체 생성과 Minor GC 사이클을 나타냅니다.
- Survivor Space: Minor GC 후 살아남은 객체가 이동하는 공간으로, 과도한 증가는 객체 수명 관리 문제를 나타냅니다.
- Old Gen: 오래 살아남은 객체가 저장되는 공간으로, 지속적 증가는 메모리 누수 가능성을 시사합니다.
중요성: 각 세대별 메모리 사용 패턴은 GC 효율성과 직결되며, 애플리케이션의 객체 생성 패턴을 이해하는 데 중요합니다.
스레드 관리 지표
Thread Counts
- 활성 스레드 수: 현재 실행 중인 스레드 수로, 급증은 병렬 작업 증가를 의미합니다.
- 데몬 스레드 수: 백그라운드 작업을 수행하는 스레드 수입니다.
- 스레드 대기 상태: 블로킹 상태의 스레드 수로, 높으면 I/O 또는 동기화 병목을 의미합니다.
중요성: 스레드 관리 상태는 동시성 처리 능력과 리소스 효율성을 결정합니다.
GC(Garbage Collection) 지표
GC Count & Duration
- Minor GC: `Eden 영역`의 가비지 컬렉션으로, 빈도가 높으면 단기 객체 생성이 많음을 의미합니다.
- Major GC: `Old 영역`의 가비지 컬렉션으로, 빈도가 높으면 메모리 압박이 심함을 의미합니다.
- STW(Stop-The-World) 시간: GC로 인해 애플리케이션이 일시 정지된 시간으로, 길면 응답성이 저하됩니다.
중요성: GC 패턴은 애플리케이션의 메모리 사용 특성과 성능에 직접적 영향을 미칩니다.
데이터베이스 연결 지표

Connection Pool Statistics
- 활성 연결 수: 현재 사용 중인 DB 연결 수로, 풀 크기의 70% 이상이면 병목 가능성이 있습니다.
- 대기 연결 수: 연결을 기다리는 요청 수로, 0보다 크면 풀 크기가 부족함을 의미합니다.
- 연결 획득 시간: DB 연결을 얻는 데 걸린 시간으로, 30ms 이상이면 일반적으로 병목입니다.
중요성: DB 연결 관리는 백엔드 성능의 핵심 요소로, 연결 풀 고갈은 전체 서비스 응답성을 크게 저하시킵니다.
HTTP 통신 지표

Request Count & Response Time
- 요청 수: 초당 처리된 HTTP 요청 수로, 갑작스런 증가는 트래픽 폭주를 의미합니다.
- 응답 시간: 요청 처리에 걸린 시간으로, 어떤 API에서 응답이 지연되는지 확인할 수 있습니다.
중요성: 사용자 경험에 직접적 영향을 미치는 지표로, SLA 준수 여부를 결정합니다.
로그 분석 지표

Log Levels & Patterns
- INFO 로그: 일반적인 애플리케이션 상태 정보로, 과도하면 I/O 부하를 유발합니다.
- WARN 로그: 잠재적 문제를 나타내며, 급증은 성능 저하의 전조일 수 있습니다.
- ERROR 로그: 실제 오류 상황으로, 발생 즉시 확인이 필요합니다.
중요성: 로그 패턴 분석은 이상 징후 조기 발견과 근본 원인 분석에 필수적입니다.
모니터링 시점과 해석 & 조치
각 지표가 어떤 의미를 가지는지 알았다면, 언제 해당 지표를 참고하면 좋고, 각 지표의 변화가 의미하는 바와 어떤 조치를 해야하는지 정리해보겠습니다.
기본 통계
Uptime/Start time
- 모니터링 시점: 시스템 가용성 및 안정성 확인
주요 지표 해석 및 조치:
- Uptime 감소
- 의미: 예상치 못한 재시작 발생
- 조치: 재시작 원인 분석, 시작 로그 검토, HA 설정 확인
- Start time 변경
- 의미: 시스템 재시작 발생
- 조치: 계획된 유지보수 확인, 충돌 로그 분석, 안정성 패턴 파악
Heap/Non-Heap Used
- 모니터링 시점: 메모리 사용 패턴 분석, OOM 방지, 메모리 누수 감지
주요 지표 해석 및 조치:
- Heap 사용률 70% 이상
- 의미: 메모리 압박 상태, GC 빈도 증가 예상
- 조치: 힙 크기 증가, 메모리 집약적 작업 최적화, 캐시 크기 조정
- Heap 사용률 지속적 증가
- 의미: 메모리 누수 가능성
- 조치: 우선 GC 로그 분석을 통해 누수 패턴 확인 후, 필요시 힙 덤프 분석, 메모리 프로파일링
- Non-Heap 사용률 급증
- 의미: 메타스페이스 부족, 클래스 로딩 이슈
- 조치: Metaspace 크기 증가, 동적 클래스 로딩 패턴 검토
CPU Usage & Load Average
- 모니터링 시점: 시스템 전반 부하 확인, 리소스 활용 상태 점검
주요 지표 해석 및 조치:
- CPU 사용률 70% 이상
- 의미: 경고 수준의 CPU 부하, 응답 지연 예상
- 조치: CPU 집약적 작업 최적화, 부하 분산, 불필요한 연산 제거
- Load Average > CPU 코어 수
- 의미: 시스템 과부하, 처리 지연 발생
- 조치: 수직/수평 확장 고려, 우선순위 낮은 작업 지연, 스로틀링 적용
- 시스템 CPU > 프로세스 CPU
- 의미: OS 레벨 경합 발생
- 조치: 커널 파라미터 튜닝, I/O 패턴 최적화, 컨텐션 지점 식별
Process Open Files
- 모니터링 시점: 리소스 누수 감지, 파일 핸들 관리 상태 확인
주요 지표 해석 및 조치:
- 파일 핸들이 ulimit의 50% 이상
- 의미: 리소스 누수 가능성
- 조치: 열린 파일/소켓 목록 확인, 명시적 close() 패턴 점검
- 파일 핸들 지속적 증가
- 의미: 파일/소켓 닫기 누락
- 조치: try-with-resources 적용, 리소스 해제 코드 검토, 핸들러 풀링
- 파일 핸들 한계(ulimit) 접근
- 의미: 리소스 고갈 임박, 시스템 장애 위험
- 조치: ulimit 임시 증가, 중요하지 않은 연결 정리, 리소스 관리 패턴 수정
JVM Statistics - Memory
G1 Eden/Old Gen/Survivor Space
- 모니터링 시점: 세부 메모리 관리 상태, GC 효율성 분석
주요 지표 해석 및 조치:
- Eden 공간 사용률 급변동
- 의미: 객체 생성/수집 사이클, 정상적 패턴
- 조치: 단기 객체 생성 패턴 최적화, Eden 크기 조정
- Old Gen 사용률 70% 이상
- 의미: Major GC 임박, 성능 저하 예상
- 조치: Old Gen 크기 증가, 장기 객체 검토, 메모리 누수 확인
- Survivor 공간 급증
- 의미: Eden에서 생존 객체 증가
- 조치: 객체 수명 주기 최적화, 조기 승격 객체 검토, Survivor 비율 조정
Direct Buffers/Memory Allocate
- 모니터링 시점: I/O 연산 패턴 분석, 메모리 할당 이슈 감지
주요 지표 해석 및 조치:
- Direct Buffer 사용량 급증
- 의미: 네이티브 메모리 사용 증가, 누수 가능성
- 조치: DirectMemory 한도 확인, 버퍼 재사용 구현, 명시적 해제 코드 추가
- 메모리 할당 급증
- 의미: 단기간 많은 객체 생성 패턴
- 조치: 객체 풀링 고려, 방어적 복사 최소화, 불변 객체 활용
- Buffer 용량 지속 증가
- 의미: 버퍼 해제 누락, 자원 관리 문제
- 조치: 명시적 `close()` 호출 확인, `try-with-resources` 사용, 자원 관리 코드 개선
Thread Counts (Daemon/Live/Peak)
- 모니터링 시점: 스레드 관리 상태 확인, 스레드 누수 감지
주요 지표 해석 및 조치:
- CPU 코어당 10-15개 이상의 활성 스레드
- 의미: 과도한 스레드 생성, 리소스 경합 가능성
- 조치: 스레드 풀 최적화, 비동기 작업 재구성, 풀 사이즈 제한
- 스레드 수 지속 증가
- 의미: 스레드 누수, 자원 관리 문제
- 조치: 스레드 생성/종료 코드 검토, 데드락 확인, 스레드 덤프 분석
- 대기 상태 스레드 증가
- 의미: 블로킹 작업 과다, 병목 현상
- 조치: I/O 작업 비동기화, 블로킹 코드 식별, 이벤트 기반 모델 고려
Eden, Survivor, Tenured Gen Space
- 모니터링 시점: 세부 메모리 영역 활용도 분석, 세대별 GC 효율성 평가
주요 지표 해석 및 조치:
- Eden Space 톱니 패턴
- 의미: 객체 생성 후 Minor GC에 의한 수집 사이클, 높은 빈도는 과도한 객체 생성 가능성
- 조치: 객체 생성 패턴 최적화, 단기 객체 캐싱, `allocation rate` 조정
- Survivor Space 안정성
- 의미: Eden에서 생존 객체의 관리 상태, 승격 정책 효율성
- 조치: 객체 수명주기 관리, 조기 승격 객체 검토, `tenuring threshold` 조정
- Tenured Gen 점진적 증가
- 의미: 장수명 객체 누적, 잠재적 메모리 누수 가능성
- 조치: 장기 실행 테스트, 참조 관리 검토, 주기적 Full GC 고려
CodeHeap 및 Metaspace
- 모니터링 시점: JIT 컴파일 코드 및 클래스 메타데이터 관리 상태 점검
주요 지표 해석 및 조치:
- CodeHeap 영역 안정성
- 의미: JIT 컴파일 최적화 코드의 메모리 관리 상태
- 조치: 대규모 애플리케이션의 경우 `ReservedCodeCacheSize` 조정 고려
- 의미: JIT 컴파일 최적화 코드의 메모리 관리 상태
- Metaspace 140MB 유지
- 의미: 클래스 메타데이터 적재 상태, 동적 클래스 로딩 영향
- 조치: 동적 프록시/리플렉션 사용 패턴 검토, `MetaspaceSize/MaxMetaspaceSize` 조정
Direct Buffers와 Memory Allocate/Promote
- 모니터링 시점: 네이티브 메모리 사용 패턴 및 메모리 승격 효율성 분석
주요 지표 해석 및 조치:
- Direct Buffers 간헐적 스파이크
- 의미: 일시적 대용량 I/O 작업, 네이티브 메모리 사용 패턴
- 조치: 버퍼 재사용 전략 검토, `MaxDirectMemorySize` 설정 확인
- Memory Allocate/Promote 스파이크
- 의미: 특정 시점의 집중적 객체 생성, 승격 압력 증가
- 조치: 해당 시점 비즈니스 로직 최적화, 객체 사전 할당 고려
Threads(스레드 관리)
- 모니터링 시점: 애플리케이션 병렬 처리 효율성, 스레드 관리 전략 평가
주요 지표 해석 및 조치:
- 스레드 수 급증 패턴
- 의미: 병렬 처리 작업 집중, 비동기 태스크 처리 구간
- 조치: 작업 유형별 전용 스레드 풀 분리 및 각 풀의 큐 크기와 스레드 개수 조정, 작업 큐 관리 전략 검토, 스케줄링 분산
- 데몬 vs 라이브 스레드 비율
- 의미: 백그라운드 작업과 사용자 요청 처리 균형
- 조치: 백그라운드 작업 우선순위 조정, 스레드 풀 격리 고려
JVM Statistics - GC
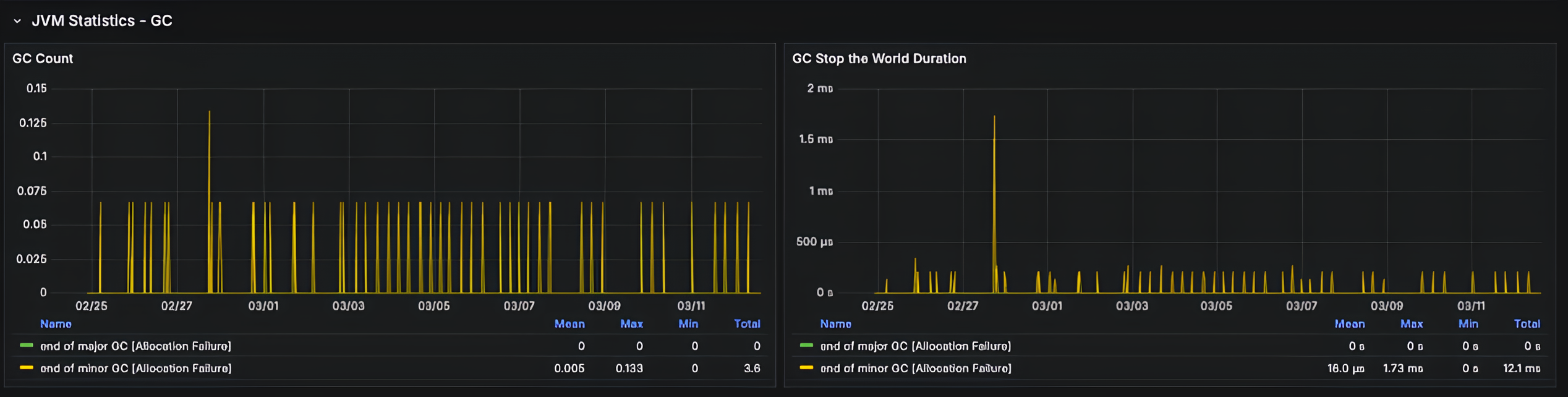
GC Count
- 모니터링 시점: 메모리 관리 이슈 감지, 가비지 컬렉션 패턴 분석
주요 지표 해석 및 조치:
- Minor GC 초당 5회 이상
- 의미: 메모리 할당 과다, Eden 공간 부족
- 조치: Eden 공간 확장, 객체 생성 패턴 최적화, 단기 객체 캐싱 검토
- Major GC 빈도 증가
- 의미: Old Gen 압박, 성능 저하 발생
- 조치: 힙 크기 증가, 장기 객체 참조 검토, 메모리 누수 분석
- GC 패턴 불규칙화
- 의미: 메모리 사용 패턴 변화, 비정상 워크로드
- 조치: 워크로드 분석, GC 알고리즘 변경 고려, 외부 부하 요인 확인
GC Stop the World Duration
- 모니터링 시점: 응답 시간 지연 원인 분석, GC 효율성 확인
주요 지표 해석 및 조치:
- STW(Stop The World) 시간 100ms 이상
- 의미: 심각한 GC 지연, 응답성 저하
- 조치: GC 튜닝 파라미터 조정, CMS/G1GC 고려, 힙 파편화 확인
- STW 평균 지속 증가
- 의미: GC 효율성 저하, 성능 문제 심화
- 조치: JVM 옵션 최적화, 세대별 크기 조정, GC 로깅 상세화
- Full GC 발생
- 의미: 극심한 메모리 압박, OOM 위험
- 조치: OOM 방지책 구현, 메모리 누수 긴급 패치, 임시 힙 증가
Database Connection Pool HikariCP Statistics

Connections Size & Usage
- 모니터링 시점: DB 연결 관리 상태 확인, 성능 병목 분석
주요 지표 해석 및 조치:
- 활성 연결 > 풀 크기의 70%
- 의미: 연결 풀 포화 임박, 병목 가능성
- 조치: 풀 크기 확장, 연결 시간 제한 설정, 불필요한 DB 작업 최적화
- 연결 대기(Pending) 발생
- 의미: 연결 풀 부족, 성능 병목 발생
- 조치: 연결 타임아웃 조정 및 풀 사이즈 점진적 확장, 읽기/쓰기 작업 분리, 인덱스 최적화
- 유휴 연결 지속적 감소
- 의미: 연결 해제 지연, 비효율적 사용
- 조치: 코드 리뷰로 연결 반환 확인, 트랜잭션 경계 최적화, 연결 누수 수정
Connection Times
- 모니터링 시점: DB 연결 성능 분석, 연결 지연 원인 파악
주요 지표 해석 및 조치:
- 연결 획득 시간 30ms 이상
- 의미: 대기 상태, 병목 현상
- 조치: 연결 타임아웃 조정 및 풀 사이즈 점진적 확장, 읽기/쓰기 작업 분리, 불필요한 트랜잭션 점유 제거, 복제본 활용
- 연결 생성 시간 증가
- 의미: DB 서버 부하 또는 네트워크 지연
- 조치: DB 서버 리소스 확인, 네트워크 지연 확인, DB 복제 상태 점검
- 연결 사용 시간 급증
- 의미: 장시간 트랜잭션, 비효율적 쿼리
- 조치: 쿼리 최적화, 트랜잭션 분할, 인덱스 상태 점검
HTTP Statistics
Request Count
- 모니터링 시점: 일일 트래픽 패턴 파악, 트래픽 폭증 감지, API 사용 추세 분석
주요 지표 해석 및 조치:
- 요청 수 급증
- 의미: 트래픽 폭주, 리소스 부족 가능성
- 조치: 오토스케일링 활성화, CDN 적용, 비필수 기능 일시 비활성화
- 특정 API 요청 집중
- 의미: 핫스팟 발생, 병목 지점 생성
- 조치: 해당 API 캐싱 적용, 부하 테스트 수행, 코드 최적화
- 요청 패턴 변화
- 의미: 사용자 행동 변화 또는 공격 패턴
- 조치: 접근 패턴 분석, WAF 규칙 검토, 비정상 IP 모니터링
Response Time
- 모니터링 시점: 성능 병목 파악, SLA 준수 여부 점검, API 성능 저하 감지
주요 지표 해석 및 조치:
- 특정 API 응답 시간 급증
- 의미: 병목 지점 식별, 특정 기능 저하
- 조치: 쿼리/트랜잭션 최적화, 부분적 비동기 처리 도입, 전용 리소스 할당
- 응답 시간 표준 편차 증가
- 의미: 성능 불안정, 일관성 저하
- 조치: 인프라 상태 점검, 배치 작업 스케줄링 최적화, 백그라운드 작업 조정
HTTP Status Codes
- 모니터링 시점: 오류 발생 패턴 확인, API 안정성 점검
주요 지표 해석 및 조치:
- 4xx 오류 증가
- 의미: 클라이언트 요청 문제, 사용 패턴 이슈
- 조치: API 문서 개선, 클라이언트 유효성 검사 강화, SDK 업데이트
- 5xx 오류 발생
- 의미: 서버 내부 오류, 시스템 불안정
- 조치: 오류 로그 분석, 서비스 재시작 고려, 롤백 또는 긴급 패치 적용
- 409 충돌 상태 코드 증가
- 의미: 동시성 제어 문제, 리소스 경합
- 조치: 낙관적/비관적 락 전략 검토, 트랜잭션 격리 수준 조정, 분산 락 메커니즘 도입
Logback Statistics
INFO Logs
- 모니터링 시점: 애플리케이션 상태 확인, 정기적 건전성 점검
주요 지표 해석 및 조치:
- INFO 로그 초당 100개 이상
- 의미: 과도한 로깅일 수 있음, 디스크 I/O 부하
- 조치: 로그 수준 조정, 로깅 빈도 제한, 중복 로그 통합
- 로그 볼륨 급증
- 의미: 특정 이벤트 발생, 비정상 행동
- 조치: 로그 필터링 적용, 관련 이벤트 조사, 로그 샘플링 설정
- 로그 발생 패턴 변화
- 의미: 애플리케이션 행동 변화, 코드 변경 영향
- 조치: 최근 코드 변경 검토, A/B 테스트 영향 확인, 사용자 패턴 분석
ERROR Logs
- 모니터링 시점: 오류 감지, 시스템 문제 파악
주요 지표 해석 및 조치:
- ERROR 로그 발생
- 의미: 시스템 오류 발생, 기능 장애
- 조치: 즉각적 원인 조사, 오류 추적 시스템 확인, 담당 팀 알림
- 특정 오류 반복
- 의미: 동일 원인 지속, 미해결 이슈
- 조치: 근본 원인 분석, 임시 해결책 적용, 영구적 수정 계획 수립
- ERROR 로그 패턴 변화
- 의미: 새로운 유형의 오류, 새로운 문제 발생
- 조치: 최근 배포 변경사항 확인, 회귀 테스트 실행, 롤백 고려
WARN Logs
- 모니터링 시점: 잠재적 문제 조기 감지
주요 지표 해석 및 조치:
- WARN 로그 급증
- 의미: 잠재적 문제 증가, 성능 저하 전조
- 조치: 관련 영역 중점 모니터링, 임계치 미세 조정, 예방적 유지보수
- WARN 후 ERROR 발생
- 의미: 문제 악화 패턴, 예측 가능한 장애
- 조치: 조기 개입 프로세스 시작, 에스컬레이션 체계 가동, 리소스 확보
- 특정 WARN 메시지 반복
- 의미: 지속적 경고 상태, 만성적 문제
- 조치: 컴포넌트 설정 검토, 임계값 조정, 해당 기능 모니터링 강화
로그 최적화 전략
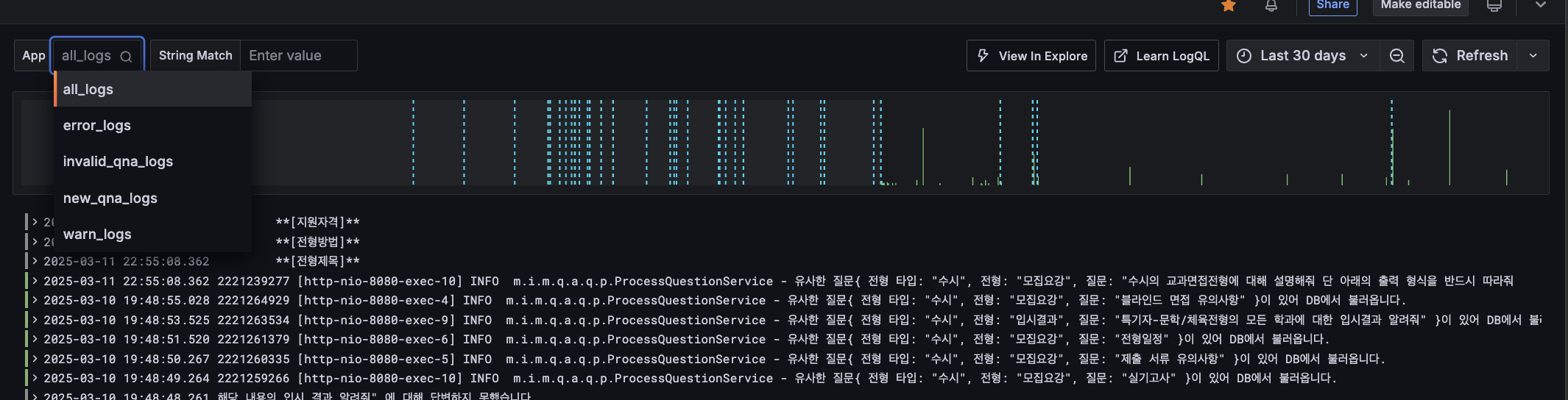
키워드 기반 로그 분류 및 필터링
Loki를 통한 로그 모니터링과 함께, 효율적인 로그 관리를 위해 Logback 설정을 최적화했습니다. Janino 표현식 필터를 활용하여 특정 키워드 기반으로 로그를 분류하고 필터링합니다.
// build.gradle
dependencies {
implementation 'org.codehaus.janino:janino:3.1.9'
}
활용 중인 Logback 설정 예시
현재 시스템에서는 다음과 같은 로그 분류 체계를 적용하고 있습니다:
- 키워드 기반 로그 분류
- `[NEW` 키워드가 포함된 로그는 `new_qna_logs` 디렉토리에 저장
- `[INVALID`키워드가 포함된 로그는 `invaild_qna_logs` 디렉토리에 저장
- 위 방식으로 특정 비즈니스 케이스에 대한 로그를 독립적으로 관리하여 분석 효율성 향상
<filter class="ch.qos.logback.core.filter.EvaluatorFilter">
<evaluator class="ch.qos.logback.classic.boolex.JaninoEventEvaluator">
<expression>message.contains("[NEW")</expression>
</evaluator>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>통합 분석 전략
상관관계 분석
- HTTP 응답 시간 증가 + DB 연결 대기
- 의미: DB 연결 풀 부족, 데이터베이스 병목
- 조치: 즉시 풀 크기 확장, SQL 최적화, 읽기 전용 쿼리 분리
- CPU 사용 증가 + GC 활동 증가
- 의미: 메모리 압박, 성능 저하
- 조치: 힙 설정 조정, 객체 생성 패턴 최적화, 코드 프로파일링
- 스레드 수 증가 + 파일 핸들 증가
- 의미: 리소스 관리 이슈, 자원 누수
- 조치: 스레드 풀 검토, 명시적 리소스 해제, 비동기 I/O 패턴 적용
- ERROR 로그 증가 + 특정 API 응답 지연
- 의미: 오류 전파, 연쇄적 장애
- 조치: 회로 차단기 패턴 적용, 폴백 메커니즘 구현, 의존성 격리
추세 분석
- 점진적 성능 저하
- 의미: 시스템 노후화, 기술 부채 누적
- 조치: 정기적 성능 최적화 일정 수립, 기술 부채 관리
- 트래픽 대비 리소스 사용 변화
- 의미: 확장성 문제, 효율성 변화
- 조치: 적절한 스케일링 정책 수립, 인프라 용량 계획
- 이상 탐지
- 의미: 비정상 패턴, 잠재적 문제
- 조치: 머신러닝 기반 이상 감지, 예방적 알림 체계 구축
마치며
위의 내용을 보면, CS 지식을 요구하는 부분이 많다는 것을 알 수 있습니다. 모니터링으로 성능개선을 하는 경험을 통해 시스템 아키텍처, 메모리 관리, 병렬 처리, 데이터베이스 최적화 등 CS 기초 지식의 실제적 중요성을 더 깊이 이해하게 되었습니다.
앞으로도 모니터링 데이터를 바탕으로 한 인사이트 도출과 성능 최적화는 지속적으로 고민하고 개선해 나가야 할 것 같습니다..
다만, 이 글에서 제시한 임계값과 조치 방법들은 몇몇 문서와 레퍼런스를 통한 허술한(?) 가이드라인으로, 실제 적용 시에는 각 시스템의 특성, 비즈니스 요구사항, 인프라 환경에 따라 적절히 조정되어야 함을 강조하고 싶습니다.
이 글이 모니터링 시스템을 구축하고 운영하는 과정에서 참고가 되었으면 좋겠습니다!
Reference
- Prometheus 공식 문서: https://prometheus.io/docs/
- Grafana 공식 문서: https://grafana.com/docs/
- Loki 공식 문서: https://grafana.com/docs/loki/latest/
- Spring Boot Actuator 메트릭 가이드: https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html
- Micrometer 문서: https://micrometer.io/docs
- "자바 메모리 관리와 GC 튜닝 가이드", https://www.oracle.com/technical-resources/articles/java/architect-evans-pt1.html
- HikariCP 성능 최적화 가이드: https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
- Amazon CloudWatch 사용 설명서: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html
- Oracle Java Concurrency Tutorial: https://docs.oracle.com/javase/tutorial/essential/concurrency/pools.html
- Oracle JVM Garbage Collection 튜닝: https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/introduction.html
- Linux 커널 문서 (파일 시스템 파라미터): https://www.kernel.org/doc/Documentation/sysctl/fs.txt
- Oracle Java Troubleshooting Guide: https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/memleaks001.html
- Baeldung HikariCP 설정 가이드: https://www.baeldung.com/hikaricp
- Baeldung 자바 스레드 풀 가이드: https://www.baeldung.com/thread-pool-java-and-guava
모든 이미지 출처: 직접 Grafana 대시보드에서 캡처한 화면입니다.



