💎 작성된 글의 프로젝트
https://github.com/MARU-EGG/MARU_EGG_BE
GitHub - MARU-EGG/MARU_EGG_BE
Contribute to MARU-EGG/MARU_EGG_BE development by creating an account on GitHub.
github.com
🚪 들어가기 전에..
프로젝트를 진행하면서 어떤 질문이 들어왔을 때 이전의 질문과 같은 질문인지 판단하는 프로세스가 필요했습니다.
이번에는 이 과정에서 어떤 삽질(?)을 했는지 기록해보겠습니다.
이번에는 Elasticsearch를 사용하지 않게 된 이유와 이를 해결하기 위해 어떤 고민을 했는지 정리해보았습니다.
다음에는 MySQL Full-Text Search와 Apache Class TFIDFSimilarity, Class CosineSimilarity 를 사용하여 문장의 유사도를 어떤 방식으로 확인했는지 작성했습니다.
💡 문제 인식
학교 입학처에서 입학시기가 되면 입학처에서는 하루 200~300통까지의 전화가 몰린다고 합니다.
이때 단순한 질문(ex. 입시 시기 알려주세요, 입학 정원 알려주세요 등등) 이 대부분을 차지하여 반복적으로 같은 대답을 하는 경우가 발생합니다.
또한 재외국민, 수시, 정시, 편입 등의 여러 정보가 홈페이지 및 입시요강에 산발적으로 존재하므로 이를 찾는데 어려움을 겪어 전화하시는 분들이 계십니다.
즉, 학교의 입학처 관계자들과 입시를 희망하는 학생 모두가 하나의 입시요강을 이용해 정보를 전달, 습득하는 상황에서 원하는 정보를 편리하게 전달 및 이용할 수 있는 방법을 찾고자 했습니다.
사용자들이 질문-대답 프로세스를 가장 쉽고 익숙하게 사용할 수 있는 방식이 챗봇이라는 판단이 들었기에 저희 서비스는 챗봇의 형태를 띄게 되었습니다.
🛎️ 서비스 목표
- 대학교에 진학을 희망하는 입시생들에게 AI 챗봇을 통해 입시와 관련한 정보를 더 빠르고 쉽게 제공하고자 합니다.
- 어드민페이지 구현을 통해 매년 유지보수를 하며 정확한 정보를 제공할 수 있도록 합니다.
🌊 대략적인 흐름


이번 글에서는 Data Server와의 통신 및 비용 부담을 줄이기 위해 같은 질문이라면 DB로 접근하고 아닌 경우에만 Data Server에게 접근하는 로직을 구현하기 위해 채택한 방법을 정리했습니다.
🤔 어떤 방식을 적용할지에 대한 고민
📌 첫 번째, Elasticsearch를 활용한 ELK Stack (결론: 비용 문제 및 데이터양에 따른 성능 오버헤드)
가장 먼저 들었던 생각은 elasticsearch 였습니다. elasticsearch(es)는 벡터 필드를 사용한 텍스트 유사도 검색을 지원하므로 질문간의 유사도를 검증하고 필요한 질문을 불러오는데 문제가 없을 것이라고 판단했습니다.
es의 경우 아파치 루씬( Apache Lucene )을 기반으로 만들어졌고 이로 인해 전문 검색(Full Text) index 및 검색 기능을 지원하는 것으로 알려졌습니다.
또한 ELK stack을 통해 가장 관심있어하는 질문을 추려내어 FAQ에 활용하기 좋겠다는 생각이 들었습니다.

다만,, 약 13만원을 달마다 지출하는 것은 대학생들에게 너무나 가혹한 일이기에 다른 방법을 찾아봐야 했습니다.
aws OpenSearch는?
대안책으로 elasticsearch와 사이가 안 좋은(?) aws의 OpenSearch가 있었지만 프리티어로 저렴하게 사용할 수 있을거란 기대와 달리 월 750 시간 이후 인스턴스를 끄지 않으면 월마다 20만원..씩 부과되는 것을 확인했기에 다른 대책이 필요한 상황이었습니다.
"Elasticsearch is Open Source, Again" Elasticsearch가 다시 오픈소스로 전환한다고 합니다.
이 글을 7월에 작성하고 프로젝트가 8월 말에 마무리 되었는데 딱 8월 30일에 이런 새로운 소식이 들렸네요!!
혹시 이 글을 미래에 보실 분들을 위해 이 글을 남깁니다.
저도 새로운 프로젝트에 사용할 일이 생긴다면 도전해보겠습니다!
수정일 2024.09.05
📌 두 번째, MySQL Full Text Index
비용적인 부담을 줄이기 위해서는 ELK stack을 사용할 수 없다는 판단이 들었고, 다른 방법으로 DB의 활용하는 방법을 고려해보았습니다.
데이터베이스 전공 수업 시간에 배웠던 Like 함수와 index(Full Text Index)를 통해 구현해보고자 했습니다.
이를 프로젝트에 적용하기 전, Like 함수와 Full Text Index 종류(자연어 검색, 불린 모드 검색, 쿼리 확장 검색) 중 어떤 방식을 사용할지 고민해보았습니다.
먼저, 성능 테스트를 간단하게 진행해보았습니다.
📍 MySQL Index VS Elasticsearch
MySQL의 성능을 비교하기 전 Elasticsearch와 MySQL의 성능은 얼마나 차이가 날지 궁금하여
- https://velog.io/@ddh963963/검색-기능-고도화-하기-3-성능-테스트 해당 블로그의 자료를 참고했습니다.
MYSQL Index Search vs Elasticsearch (20만 건 이상)

MYSQL Full-Text-Search vs Elasticsearch (100건 이하)

위의 블로그에서는 20만건 이상일 경우 Full Text-Search를 사용하기 어려워 Index Search를 사용했고, 이 결과를 봤을 때 대용량의 데이터가 아닌 우리의 프로젝트에서는 MySQL의 Full Text Search를 사용하는 판단이 맞다고 판단했습니다.
📍 Like 함수 검색 VS Full Text Index를 통한 검색
Like 함수 검색
- 실행 결과

약 100개 정도의 질문을 임의로 저장하고 Like 함수가 포함된 쿼리를 실행한 결과
전체 실행 시간: 168ms
쿼리 실행 시간: 30ms
검색 결과를 가져오는데 걸린 시간: 138ms
Full Text Index를 통한 검색
- Full Text Index 생성

- 실행 결과

약 100개 정도의 질문을 임의로 저장하고 Full Text Index를 통해 쿼리를 실행한 결과
전체 실행 시간: 72ms
쿼리 실행 시간: 17ms
검색 결과를 가져오는데 걸린 시간: 55ms
결과를 보면 전체 실행 결과는 2배 이상, 검색 결과를 불러오는데 2배 이상이 든 것을 알 수 있었습니다.
왜 Like 함수는 더 느릴까?
B+Tree 특성상 Leaf node의 데이터는 순차적으로 저장됩니다.
이때 %연산이 좌측에 있게 되면 Leaf node를 전부 찾아보는 Full Scan 문제가 발생하게 되기 때문에 늦어진다고 합니다.
이를 해결하기 위한 방법이 Full Text Index이고, MySQL은 ngram Full-Text parser을 built-in으로 지원한다고 합니다.
아래의 공식문서 사진처럼 Full Text Index에는 Natural Language Full-Text Searches과 Boolean Full-Text Searches, Full-Text Searches with Query Expansion 이 있습니다.

📍 자연어 검색(Natural Language Full-Text Searches)
select *, match(question) against('원서 접수 수시' IN NATURAL LANGUAGE MODE) AS 점수
from questions_answers
where match(question) against('원서 접수 수시' IN NATURAL LANGUAGE MODE);자연어 검색은 정확한 단어를 검색해줍니다.
위의 예시처럼 ‘원서 접수 수시’를 검색하게 되면 원서, 접수, 수시의 단어가 들어있는 대답을 가져오게 됩니다.


자연어 검색의 경우 띄어쓰기를 기준으로 정확한 단어감 검색되기 때문에 능동적인 검색이 불가능하다는 단점이 존재합니다.
📍 불린 모드 검색(Boolean Full-Text Searches)
불린 모드 검색에서는 자연어 검색과 달리 검색에 option을 부여할 수 있어 자연어 검색보다 능동적인 검색이 가능합니다.
+ : 검색에서 필수가 되는 단어유사도에 따라 점수를 부여하고 이에따라 정렬됩니다.
select *, match(question) against('+원서 +접수 수시' IN BOOLEAN MODE) AS 점수
from questions_answers
where match(question) against('+원서 +접수 수시' IN BOOLEAN MODE);
원서, 접수 가 필수로 포함됨(자연어와 같음)
유사도에 따라 점수를 부여하고 이에따라 정렬됩니다.
- : 검색에서 제외가 되는 단어
select *, match(question) against('+원서 +접수 -수시' IN BOOLEAN MODE) AS 점수
from questions_answers
where match(question) against('+원서 +접수 -수시' IN BOOLEAN MODE);수시를 제외한 원서, 접수가 포함됨

~ : 검색 부정 -은 제외시키지만 ~ 은 윗 순위로 정렬
select *, match(question) against('원서 접수 ~정시' IN BOOLEAN MODE) AS 점수
from questions_answers
where match(question) against('원서 접수 ~정시' IN BOOLEAN MODE);원서, 접수를 포함하고 정시가 포함된 행을 우선 순위로 둠

* : 부분 검색
select *, match(question) against('입학* 시험*' IN BOOLEAN MODE) AS 점수
from questions_answers
where match(question) against('입학* 시험*' IN BOOLEAN MODE);입학, 시험 을 포함하도록 검색(시험은 ~, 입할할 때~ 등)

“” : 부분 검색이지만 “” 안에 있는 구문과 정확히 일치할 때 검색
@distance : InnoDB 전용, 단어들 간의 거리를 지정
> < : 단어의 관련성 기여도를 변경
( ) : 단어 그룹화를 위한 괄호
수시를 제외한 원서, 접수가 포함
최소 검색 단어 수 조절
- docker-compose를 사용하신다면 command 부분에
"--innodb_ft_min_token_size=1"를 추가하시면 됩니다.
services:
maru-egg-db:
image: mysql:8.0
platform: linux/x86_64
ports:
- "3316:3306"
environment:
MYSQL_ROOT_PASSWORD: rpw
MYSQL_DATABASE: db
MYSQL_USER: user
MYSQL_PASSWORD: pw
TZ: Asia/Seoul
volumes:
- ./db/mysql/data:/var/lib/mysql
- ./db/mysql/config:/etc/mysql/conf.d
- ./db/mysql/init:/docker-entrypoint-initdb.d
command:
- "--innodb_ft_min_token_size=1"- 저의 경우 개발 서버 및 배포 서버에서는 aws의 RDS를 사용할 예정이라 파라미터 그룹에서 innodb_ft_min_token_size를 1로 변경해주었습니다.
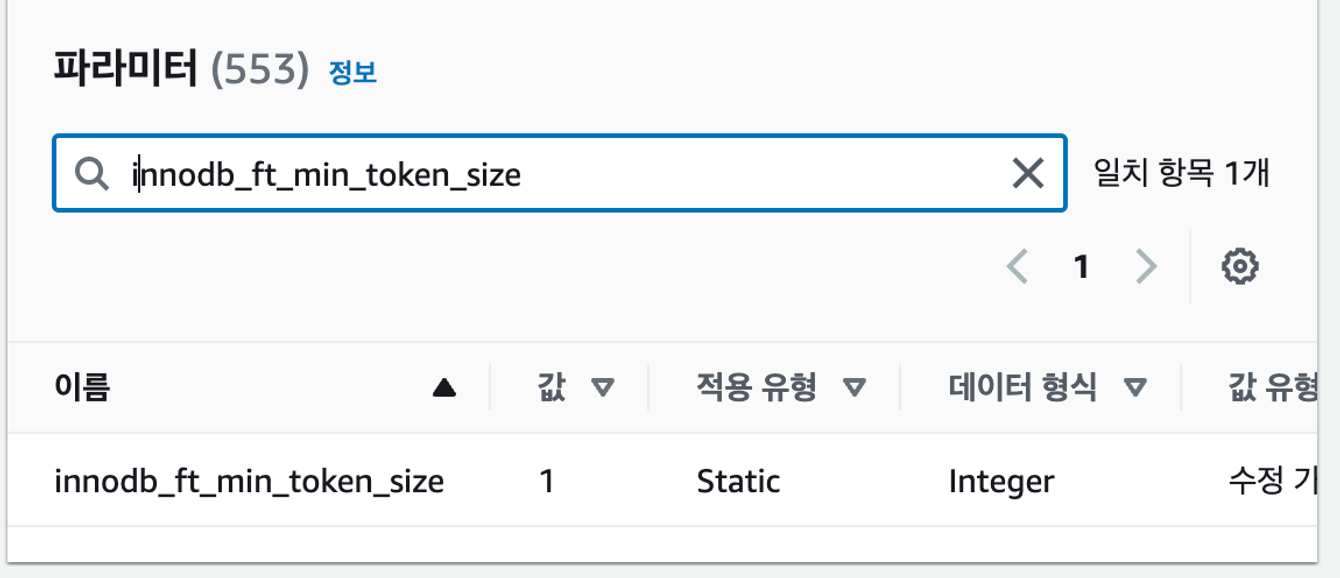
SHOW VARIABLES LIKE 'innodb_ft_min_token_size';를 통해 확인할 수 있습니다.

더 많은 정보는 MySQL 공식 Documentation에 잘 나와있으니 넘어가겠습니다 ☺️
https://dev.mysql.com/doc/refman/9.0/en/fulltext-search.html
Full text Index를 이용해서 유사한 문장을 확인할 수 있다는 것을 알았습니다.
그러나 위에 SQL 쿼리를 보신 분들은 아시겠지만 명사를 중심으로 검색한 것을 알 수 있습니다.
문장을 그대로 검색하게 되면 어떤 조사를 사용하는지, 어떤 목적어를 사용하는지에 따라 유사도를 검사하기 어렵기 때문에 이를 해결하기 위한 방법을 더 고민해보았습니다.
💡 해결해야할 문제
질문의 형태는 절대 예상할 수 없다고 가정했고, 이를 위해서는 각 질문을 정규화해서 정돈된 질문의 형태로 바꿔주는 작업이 필요합니다.
예를 들면, ‘수시에서 모집 기간 알려주세욬ㅋㅋㅋ’ 과 같이 들어온 질문과 ‘수시 모집 기간’ 이라고만 작성된 질문은 같은 의미이지만 그대로 사용할 경우 다른 질문이라고 추측하게 됩니다.
또한, MySQL의 Full-Text Search로 문장의 유사도 검증이 미흡하다는 생각이 들었습니다. (Boolean Mode의 옵션만으로 해결할 수도 있지만 그렇게 되면 DB의 복잡도가 높아져 유지보수가 어렵지 않을까 판단했습니다.
다음 블로그에서 다룰 주제이지만, MySQL에서도 텍스트 유사도를 검증하는 알고리즘인 TF-IDF를 지원합니다..!

https://dev.mysql.com/doc/refman/9.0/en/fulltext-boolean.html 에서 Relevancy Rankings for InnoDB Boolean Mode Search 부터 확인한다면 알 수 있습니다.
그럼에도 applicaton Level에서 해결하고자 했는데, 그 이유는 DB에서의 작업이 복잡해질 수록 DBA가 없는 시점에서 유지보수, 재사용성에 안 좋은 영향이 갈 것이라고 생각했습니다.
📒 Reference
'개발 일지 > Maru-egg (입시 정보 안내 RAG 챗봇)' 카테고리의 다른 글
| 모니터링으로 성능 개선점 찾기 (with Prometheus, Grafana, Loki, Promtail) (1) | 2025.03.13 |
|---|---|
| DB Connection 점유 줄이기: OSIV와 단계적 CQRS 그리고 트랜잭션 설계 (0) | 2024.11.23 |
| Spring, BE | Apache Tomcat 바로 알기 + 웹서버(Nginx와 Apache 비교)를 두는 이유 (3) | 2024.08.13 |
| Java & Spring | Swagger 커스텀 ApiResponse 어노테이션 사용기(+ Reflection을 통한 문제 해결) (3) | 2024.07.17 |
| 프로젝트 & BDP | Java(Spring)에서 TF-IDF와 Cosine Similarity를 활용한 문장간 유사도 측정 방법 (1) | 2024.07.07 |



