들어가기 전…
JPA를 사용해 프로젝트를 진행하던 중 데이터를 한번에 여러개 저장해야하는 경우는 많이 경험했기에 save 를 통해 데이터를 반복적으로 저장하는 것보다 saveAll 이 성능이 좋다는 것을 경험적으로 알 수 있었습니다. 오늘은 save와 saveAll의 코드를 분석하고 성능차이의 이유를 알아보려고 합니다. (쓰기 지연에 대하여)
또한, saveAll에 hibernate 설정으로 어떻게 JPA로 쉽게 Batch Insert를 적용하는지 알아보고자합니다.
아래는 해당 블로그 글을 적용한 프로젝트입니다.
https://github.com/Findy-org/FINDY_BE
GitHub - Findy-org/FINDY_BE: Findy, 순간을 찾아 연결하다
Findy, 순간을 찾아 연결하다. Contribute to Findy-org/FINDY_BE development by creating an account on GitHub.
github.com
Batch Insert를 직접 Native Query를 통해 작성할 수 있지만, 이는 유지보수와 코드 복잡성에 안 좋은 영향을 주게 됩니다.
public void nativeBulkInsert(List<MyEntity> entities) {
String sql = "INSERT INTO my_entity (column1, column2) VALUES (?, ?)";
entityManager.getTransaction().begin();
// 직접 컬럼을 하나하나 지정해줘야하며, Entity가 달라질 경우 각 컬럼에 따른 바인딩 문제 발생
for (int i = 0; i < entities.size(); i++) {
entityManager.createNativeQuery(sql)
.setParameter(1, entities.get(i).getColumn1())
.setParameter(2, entities.get(i).getColumn2())
.executeUpdate();
if (i > 0 && i % BATCH_SIZE == 0) {
entityManager.flush();
entityManager.clear();
}
}
entityManager.getTransaction().commit();
}
이는 JPA의 쓰기 지연 SQL 을 사용한다면 손쉽게 해결할 수 있습니다. 쓰기 지연을 이해하기 전 JPA의 Transaction과 영속성 컨텍스트를 save메서드들을 보며 이해해보겠습니다.
먼저, Proxy 패턴과 @Transactional의 작동 방식에 대해 알아보겠습니다.
Proxy 패턴과 @Transactional의 작동 방식
왜 save와 saveAll에 대해 알아보는데 Proxy 패턴과 @Transactional의 작동 방식을 알아야할까요? 그 이유는 다음과 같습니다.

이 코드를 보면 @Transactional 이 붙어있는 것을 알 수 있습니다.
Spring에서 @Transactional을 사용하는 메서드는 Proxy 패턴을 통해 트랜잭션을 관리합니다.
@Transactional이 적용된 메서드는 Spring이 AOP Proxy 객체로 감싸고, 이를 통해 메서드 호출 전후에 트랜잭션 시작 및 종료 코드가 자동으로 삽입됩니다.
AOP와 Proxy 객체의 역할
Spring은
@Transactional,@Cacheable,@Async등의 애노테이션이 붙은 메서드를 호출할 때 원래 객체 대신에 프록시 객체를 사용하여 메서드 호출을 감쌉니다.
이 프록시 객체는 원본 객체에 대한 호출을 대리하며, 호출 전후로 필요한 AOP 기능을 수행할 수 있는 코드를 삽입합니다.
예를 들어,@Transactional애노테이션이 붙은 메서드는 호출 전 트랜잭션을 시작하고 호출 후 트랜잭션을 커밋 또는 롤백합니다.
Proxy 객체의 작동 방식
프록시 객체는 원본 객체를 대리하여 메서드를 호출하며, 메서드 호출 전후에 추가 로직을 실행할 수 있는 위치를 제공합니다.
예를 들어, 다음과 같은 방식으로 동작할 수 있습니다:
프록시 생성: Spring이 @Transactional이 붙은 객체를 감싸는 Proxy 객체(ProxyEntityRepository)를 생성합니다.
메서드 호출 가로채기: 메서드 호출 시 Proxy가 중간에서 해당 호출을 가로챕니다.
횡단 관심사 적용: Proxy는 트랜잭션 시작 코드 등을 호출 전후에 삽입한 후 원본 객체의 메서드를 호출합니다.
결과 반환: 트랜잭션이 종료되고 결과가 반환되거나 예외가 발생하면 필요한 롤백 및 커밋 처리를 수행합니다.
Spring AOP와 Proxy에 대한 자세한 내용은 아래의 글을 참고해주세요!
https://hoya324.tistory.com/entry/Spring-Spring-AOP-1
그럼 이제 트랜잭션의 관점에서 save와 saveAll의 코드를 통해 동작 방식을 알아보겠습니다.
트랜잭션의 관점: JPA의 save()와 saveAll()

save() 메서드는 @Transactional이 자동으로 적용되어 있어 개별 호출 시마다 트랜잭션이 시작되고 종료됩니다.
단건 save의 경우에는 오버헤드가 없지만 이를 사용해 다건 처리를 한다면 문제가 될 것입니다.
즉, save가 1000번 호출된다면 1000개의 트랜잭션이 생성됩니다.
각 트랜잭션마다 별도의 시작과 종료 과정이 필요하므로, 이런 방식은 트랜잭션 오버헤드가 상당히 큽니다.

반면에 saveAll 메서드는 엔티티 list를 반복해서 처리하면서 save를 호출하지만, saveAll 메서드 자체가 @Transactional 에 묶여 있다는 것을 알 수 있습니다.
즉, saveAll 메서드는 한 번의 트랜잭션 안에서 모든 save 호출이 실행합니다.
이는 내부적으로 반복되는 save 메서드가 Proxy에서 관리되지 않고 단일 트랜잭션 내에서 처리됨을 의미합니다.
이로인해, saveAll은 단 한 번의 트랜잭션 오버헤드만 발생하게 됩니다.
중요한 점은 Proxy 객체 내부에서 호출된 메서드는 AOP 트랜잭션이 적용되지 않는다는 점입니다.
Proxy 객체에서 saveAll() 메서드를 통해 save()가 호출될 때 각각의 트랜잭션이 발생하지 않는 이유도 여기에 있습니다.
관련자료: Baeldung, Thorben Janssen
이번에는 JPA의 핵심 개념 중 하나인 영속성 컨텍스트의 관점으로 차이를 알아보겠습니다.
영속성 컨텍스트: JPA의 save()와 saveAll()
save와 saveAll 메서드는 모두 @Transactional로 트랜잭션이 시작된 상태에서 실행되므로, 같은 영속성 컨텍스트 내에서 작동하게 됩니다.
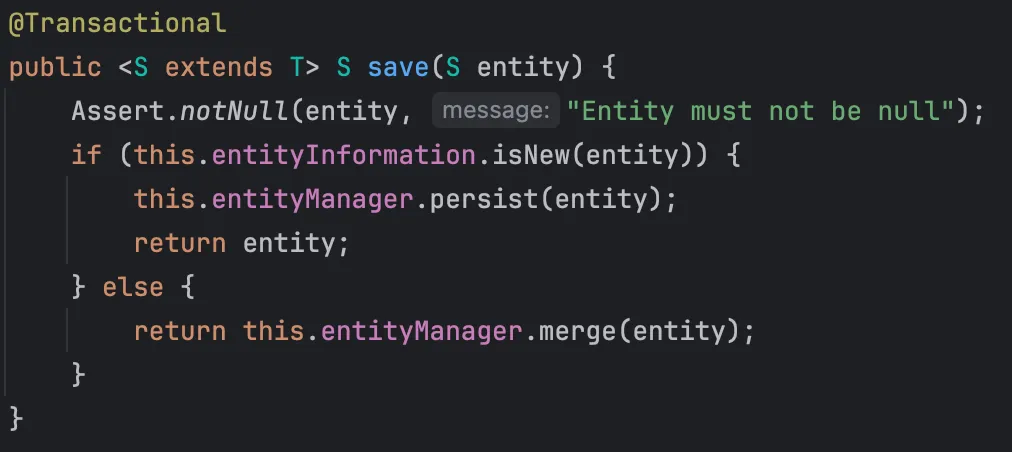
save 메서드는 개별 엔티티를 처리할 때, entityInformation.isNew(entity)를 통해 엔티티가 새 엔티티인지 확인하고, 새 엔티티라면 entityManager.persist(entity)를 호출하여 영속성 컨텍스트에 엔티티를 추가합니다.
이미 존재하는 엔티티인 경우에는 entityManager.merge(entity)를 통해 영속성 컨텍스트에 병합하여 업데이트합니다.
saveAll은 여러 엔티티를 save 메서드를 통해 하나씩 처리하면서 각 엔티티를 영속성 컨텍스트에 추가합니다.
따라서 saveAll은 호출되는 엔티티의 개수만큼 영속성 컨텍스트에 persist 또는 merge 작업을 수행하게 됩니다.
여기서 핵심은 saveAll이 실행될 때 각각의 엔티티가 개별적으로 영속성 컨텍스트에 추가된다는 점입니다. 트랜잭션이 끝나기 전까지는 플러시되지 않고, 트랜잭션이 커밋될 때 일괄적으로 디비에 반영됩니다.
이를 쓰기 지연(Transactional Write-Behind) 이라고 합니다.
JPA의 쓰기 지연 (Transactional Write-Behind)
JPA에서 엔티티를 저장할 때, 즉시 데이터베이스에 반영되지 않고 쓰기 지연(Write-Behind) 메커니즘을 통해 효율적으로 처리됩니다. 이 메커니즘은 JPA의 엔티티 매니저(EntityManager)가 트랜잭션이 끝나기 전까지 모든 변경 사항을 1차 캐시와 쓰기 지연 SQL 저장소에 보관해두고, 트랜잭션이 커밋될 때 한꺼번에 데이터베이스에 적용하는 방식입니다.
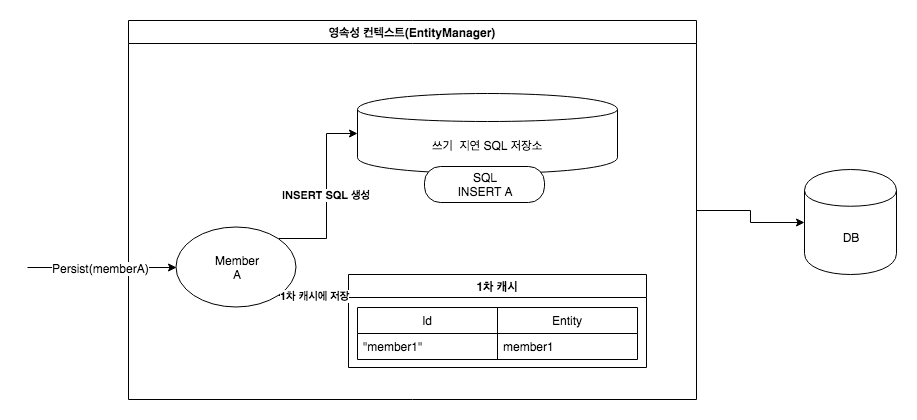
엔티티의 영속화 (Persisting an Entity): 엔티티를 persist 메서드로 영속화하면, 해당 엔티티는 즉시 데이터베이스에 저장되는 것이 아니라 1차 캐시에 저장됩니다.
동시에, INSERT SQL 쿼리가 쓰기 지연 SQL 저장소에 추가됩니다. 예를 들어, 회원 A를 영속화하면 회원 A의 정보로 만든 INSERT SQL 쿼리가 쓰기 지연 SQL 저장소에 보관됩니다.
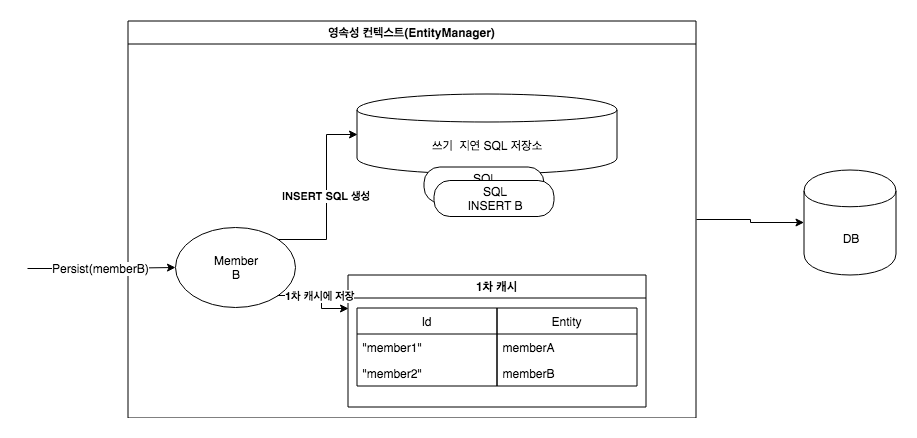
여러 엔티티의 처리: 추가적으로 회원 2를 영속화하면, 마찬가지로 회원 2에 대한 INSERT SQL 쿼리가 생성되어 쓰기 지연 SQL 저장소에 저장됩니다.
이처럼 여러 엔티티를 개별적으로 영속화하더라도, JPA는 데이터베이스와의 직접적인 상호작용을 지연하고, 생성된 SQL을 내부 저장소에 모아둡니다.
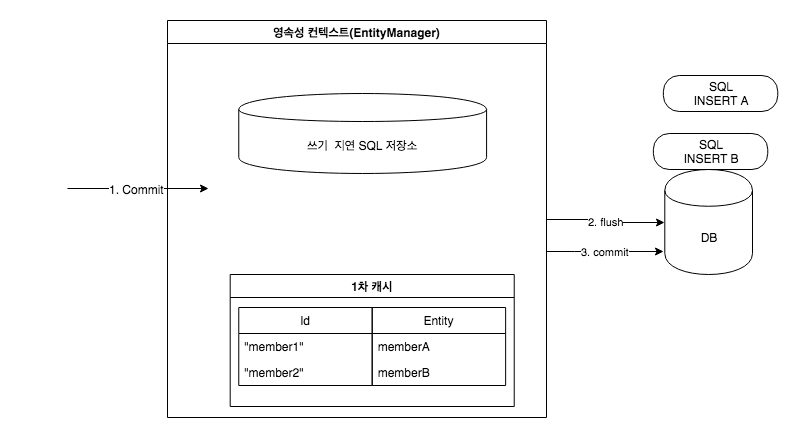
플러시 (Flush): 트랜잭션이 커밋되기 전, flush 작업이 수행됩니다.
플러시는 영속성 컨텍스트의 변경 사항을 데이터베이스에 동기화하는 과정입니다. 이때 쓰기 지연 SQL 저장소에 쌓여 있던 INSERT, UPDATE, DELETE 등의 SQL 쿼리들이 데이터베이스로 보내집니다. 그러나 트랜잭션이 끝나기 전까지는 실제로 커밋되지 않습니다.
트랜잭션 커밋 (Transaction Commit): 트랜잭션이 커밋될 때, 엔티티 매니저는 쌓여 있던 SQL 명령어를 일괄 실행합니다.
이 과정에서 데이터베이스는 최종적으로 변경 사항을 반영하게 됩니다.
JPA는 이 모든 과정을 내부적으로 처리하기 때문에, 사용자는 코드에서 직접 데이터베이스 작업을 호출할 필요 없이 트랜잭션 단위로 일괄 처리가 가능합니다.
이를 활용한 Batch insert는 이런 이유로 관리에 용이하다는 장점을 가지게 됩니다.
Flush가 붙은 save
saveAll: 트랜잭션 범위 내에서 모든 엔티티를 영속성 컨텍스트에 저장하지만, 플러시는 트랜잭션 종료 시점에 일괄적으로 수행됩니다. 즉,saveAll은 영속성 컨텍스트에 엔티티를 추가하기만 하고, 데이터베이스에 즉시 반영하지 않습니다.
saveAllAndFlush:saveAll메서드를 통해 엔티티들을 영속성 컨텍스트에 추가한 후, 즉시flush()를 호출하여 영속성 컨텍스트의 변경사항을 데이터베이스에 반영합니다. 이로 인해 데이터베이스 상태가 트랜잭션이 끝나기 전에 반영됩니다.
이제 saveAll의 한계와 이를 보완한 Batch Insert에 대해 알아보겠습니다.
Batch Insert
사실 Batch Insert는 거창한 것이 아닌 SQL은 insert 문을 단건이 아닌 여러 레코드를 한번에 저장하는 방식입니다.
단일 INSERT SQL 예시
INSERT INTO ITEM (ID, NAME, DESCRIPTION) VALUES (1, 'Item A', 'Description for Item A');
Bulk INSERT SQL 예시
INSERT INTO ITEM (ID, NAME, DESCRIPTION)
VALUES
(1, 'Item A', 'Description for Item A'),
(2, 'Item B', 'Description for Item B'),
(3, 'Item C', 'Description for Item C');
구현 코드
실제 코드에는 직접 구현을 통해 Bulk Insert를 적용하진 않았습니다. 적용단계에서는 간단한 hibernate 적용 후 saveAll()을 실행하면 bulk insert를 적용할 수 있습니다.
먼저 hibernate에서 어떻게 구현되어있는지 공식 가이드를 통해 알아보겠습니다.
아래의 코드는 hibernate 문서를 참고해서 작성되었습니다.
private static final int BATCH_SIZE = 1000;
private final EntityManagerFactory entityManagerFactory;
@Override
public List<T> bulkInsert(List<T> entities) {
EntityManager entityManager = null;
EntityTransaction transaction = null;
try {
entityManager = entityManagerFactory.createEntityManager();
transaction = entityManager.getTransaction();
transaction.begin();
for (int i = 0; i < entities.size(); i++) {
if (i > 0 && i % BATCH_SIZE == 0) {
entityManager.flush();
entityManager.clear();
}
entityManager.persist(entities.get(i));
}
transaction.commit();
} catch (RuntimeException e) {
if (transaction != null && transaction.isActive())
transaction.rollback();
throw e;
} finally {
if (entityManager != null) {
entityManager.close();
}
}
return entities;
}
코드를 보면 단 한 번의 트랜잭션 오버헤드만 발생하도록 구현되었고, BATCH_SIZE마다 flush와 clear를 호출하여 트랜잭션 내에서 데이터베이스에 반영합니다.
간단하게 설명하자면
flush(): 현재 영속성 컨텍스트에 있는 변경 사항을 데이터베이스에 반영하지만 트랜잭션은 유지됩니다.clear(): 영속성 컨텍스트를 비워서 메모리를 확보합니다. 또한 데이터 정합성 문제를 예방합니다.
해당 로직으로 BATCH_SIZE마다 다건 insert문이 수행되게 되는 방식입니다. 이로써 하나의 트랜잭션에서 매 insert마다 flush 되는 것이 아닌 batch 단위의 flush가 일어나는 것으로 성능을 향상시킬 수 있다고 이해했습니다.
이를 JPA에 적용하는 것은 더욱 간단합니다.
설정 방법
application.yml
spring:
jpa:
properties:
hibernate:
jdbc.batch_size: 1000 # 한 번에 실행할 배치 SQL 문의 개수
order_inserts: true # INSERT 문을 ID 순으로 정렬하여 배치 처리
order_updates: true # UPDATE 문을 ID 순으로 정렬하여 배치 처리
batch_versioned_data: true # 버전이 있는 엔티티도 배치 처리 가능하게 설정
jdbc.lob.non_contextual_creation: true # LOB 데이터를 컨텍스트 외부에서도 생성 가능하게 설정
각 설정에 대한 설명
jdbc.batch_size: 1000
- 설명: insert 문의 크기, 즉 SQL 문의 수를 1000으로 설정합니다.
- 기대 효과: 여러 INSERT 또는 UPDATE 문을 한 번에 전송하여 네트워크 트래픽과 데이터베이스 작업 부하를 줄일 수 있습니다.
order_inserts: true
설명: INSERT 문을 ID 순서로 정렬하여 배치 작업에 포함합니다.
효과: ID 순으로 정렬되어 인덱스가 효율적으로 작동하므로 성능이 향상됩니다.
order_updates: true
설명: UPDATE 문을 ID 순서로 정렬하여 배치 작업에 포함합니다.
효과: UPDATE 작업 시 효율적으로 인덱스를 사용해 성능을 높일 수 있습니다. 저는 Update에도 적용할 예정이라 설정했습니다.
batch_versioned_data: true
설명: @Version 필드가 있는 엔티티도 배치 작업이 가능하도록 설정합니다.
효과: 버전 관리되는 엔티티를 배치로 처리할 수 있어 성능이 최적화됩니다.
jdbc.lob.non_contextual_creation: true
설명: LOB 데이터(BLOB, CLOB)를 컨텍스트 외부에서도 생성할 수 있도록 설정합니다.
효과: 특정 데이터베이스에서 LOB 데이터를 더 효율적으로 처리할 수 있습니다.
Bulk Insert 성능 테스트
Bulk Insert test
아래와 같이 10, 100, 1000, 10000, 100000 개의 insert를 Bulk Insert 설정 x, Batch Size를 100으로 설정하고 Test 해보았습니다.
@DisplayName("bulkInsertPlaces() 성능 테스트")
@ParameterizedTest
@ValueSource(ints = {10, 100, 1000, 10000, 100000})
void testBulkInsertPlacesPerformance(int entityCount) {
testPlaces = generateTestPlaces(entityCount);
long startTime = System.nanoTime();
placeRepository.saveAll(testPlaces);
long endTime = System.nanoTime();
System.out.println(
"Time taken by bulkInsertPlaces() with " + entityCount + " entities: " + (endTime - startTime) / 1_000_000
+ " ms");
}
Bulk Insert 설정 x (1개는 warm up을 목적으로 수행)

Batch Size 100

→ 약 1.5 ~ 3배 성능 향상을 확인할 수 있었습니다.
✨ 이슈
PostgreSQL을 사용한 이유와 Sequence 전략의 선택
이슈 관련 stack overflow: https://stackoverflow.com/questions/27697810/why-does-hibernate-disable-insert-batching-when-using-an-identity-identifier-gen/27732138#27732138
Hibernate는 IDENTITY 전략을 사용할 때 배치 INSERT를 비활성화하는 이슈가 있었습니다.
이는 IDENTITY가 데이터베이스에서 자동으로 ID를 생성하는 과정에서, 각 INSERT가 실행되기 전까지 ID 값을 알 수 없기 때문입니다.
이로 인해 트랜잭션 쓰기 지연 (Transactional Write-Behind) 전략이 제한되고, 효율적인 배치 처리가 어려워집니다.
이러한 이유로 저는 SEQUENCE 전략을 사용하고자 했고 SEQUENCE 전략을 지원하지 않는 MySQL이 아닌 PostgreSQL을 적용했습니다.
물론 MySQL로 IDENTITY 전략을 사용하면서 해결할 수는 있지만, 저는 개발 초기 단계였고 복잡성이 증가하는 것보다는 더 적합한 Database를 사용하는 것이 좋다고 판단했습니다.
Kotlin SQL Framework Exposed로 해결한 블로그
https://cheese10yun.github.io/archives/5/
SEQUENCE 전략은 데이터베이스에서 별도의 시퀀스 테이블을 통해 ID를 관리합니다. 이를 통해 Hibernate는 미리 ID 값을 예측하여 배치 INSERT를 효율적으로 처리할 수 있습니다.
정리하자면
- 배치 INSERT 지원: SEQUENCE 전략은 ID 값을 미리 할당할 수 있어 배치 INSERT가 가능하며, 이는 성능을 크게 향상시킵니다.
- 고성능 ID 생성: SEQUENCE는 단순하고 빠르게 ID를 생성할 수 있어 대량 데이터 입력 작업에 유리하기 때문에 적합하다고 판단했습니다.
마무리하며…
Bulk Insert 방식을 도입하며 JPA를 활용한 효율적인 데이터 관리 방안을 탐구할 수 있었습니다.
일반적으로 단일 또는 소량의 데이터 저장에는 save나 일반적인 saveAll 메서드를 사용해도 성능상 큰 문제가 없지만, 대량 데이터를 처리할 때는 트랜잭션 오버헤드와 영속성 컨텍스트 관리가 성능 저하의 원인이 될 수 있습니다. 이를 해결하기 위해 Bulk Insert 방식을 적용했고, 약 1.5~ 3배의 성능 향상을 이끌 수 있었습니다. 또한 insert되는 개수가 증가할 수록 더욱 격차가 버러지는 것도 확인할 수 있었습니다.
다만 한 가지 걱정되는 것은, Bulk Insert 코드를 봤을 때 영속성 컨텍스트 관리를 생략하여 성능을 향상시키는 장점이 있지만, JPA의 변경 감지 기능을 사용할 수 없게 되므로 데이터 정합성 관리에 취약할 것이라는 생각이 들었습니다.
참고자료
- https://cheese10yun.github.io/spring-batch-batch-insert/
- https://stackoverflow.com/questions/27697810/why-does-hibernate-disable-insert-batching-when-using-an-identity-identifier-gen/27732138#27732138
- https://cheese10yun.github.io/jpa-batch-insert/https://docs.jboss.org/hibernate/orm/5.4/userguide/html_single/Hibernate_User_Guide.html#batch-jdbcbatchJPA Bulk Insert Save Performance by Noah Tech
- MySQL 8.0 Reference Manual: Optimizing INSERT Statements
- https://velog.io/@morningstar/load-data
- https://velog.io/@yhlee9753/JPA-영속성-컨텍스트Persistence-Context
'Develop > Spring' 카테고리의 다른 글
| Spring Boot에서 Access Token으로 인증 구현하기: Filter, SecurityContext와 @AuthenticationPrincipal활용 (0) | 2024.10.06 |
|---|---|
| Spring | 🔥 Spring 프레임워크의 주요 어노테이션 (1) | 2024.09.24 |
| Spring | Spring MVC 패턴 - HTTP 요청을 받고 응답하기까지의 전 과정(2) (1) | 2024.09.05 |
| Spring | Spring MVC 패턴 - MVC와 서블릿 (1) (0) | 2024.09.05 |
| Spring | Spring AOP의 동작원리와 JDK Dynamic Proxy vs CGLIB Proxy 비교 및 Spring AOP와 AspectJ 비교 (0) | 2024.09.05 |



