💎 작성된 글의 프로젝트
https://github.com/MARU-EGG/MARU_EGG_BE
GitHub - MARU-EGG/MARU_EGG_BE
Contribute to MARU-EGG/MARU_EGG_BE development by creating an account on GitHub.
github.com
🚪 들어가기 전에..
지난 번에는 Elasticsearch를 사용하지 않게 된 이유와 이를 해결하기 위해 Full-Text Inedx를 사용한 이유, 앞으로 개선점에 대해 다뤘습니다.
🎈 저번 블로그 보기
https://hoya324.tistory.com/56
프로젝트 | 텍스트 유사도 검색 어떻게 구현할까?(1) - Elasticsearch를 안 쓴 이유와 MySQL Full Text Index
💎 작성된 글의 프로젝트https://github.com/MARU-EGG/MARU_EGG_BE GitHub - MARU-EGG/MARU_EGG_BEContribute to MARU-EGG/MARU_EGG_BE development by creating an account on GitHub.github.com 🚪 들어가기 전에..프로젝트를 진행하면서
hoya324.tistory.com
이번에는 MySQL Full-Text Search와 Apache Class TFIDFSimilarity, Class CosineSimilarity 를 사용하여 문장의 유사도를 어떤 방식으로 확인했는지 작성해보겠습니다.
🤔 문장 간의 유사도를 어떤 방법으로 확인할 것인가?
📌 텍스트의 유사도를 컴퓨터가 이해하려면?
NLP(Natural Language Processing, 자연어 처리) 은 큰 의미로 봤을 때 컴퓨터가 이해할 수 있는 방식으로 자연어를 처리하는 것을 말합니다.
즉, 한글 텍스트를 NLP 작업을 하기위한 프로세스를 계획해보겠습니다.
📍 한글 텍스트 필요한 데이터 추출 방법 고민
한국어는 영어와 다른 ‘교착어’의 특징을 가진 언어입니다. 간단하게 한국어의 특징을 한번 정리해보겠습니다.
- 단어들의 순서가 바뀌어 표현될 수 있다.
- 명사에 접사가 붙으면 문장이 다른 의미로 변경됩니다.
- 띄어쓰기에 따라 문장의 의미가 달라진다.
하나의 예시로 한글이 얼마나 컴퓨터가 이해하기 어려운 언어인지 알 수 있습니다..
한구거 버뇩 방햬긔가 굉하장다
한글에서 질문의 핵심은 무엇인가?
한국어 질문에서 명사의 역할
관련 문서: https://www.howtostudykorean.com/unit1/unit-1-lessons-17-25-2/lesson-22/
- 한국어 질문에서 명사는 주로 질문의 핵심적인 요소로 작용합니다.
- 예를 들어, “무엇을 먹었어요?“와 같은 질문에서 “무엇”은 명사 역할을 하며, 질문의 주된 내용을 결정합니다. 이는 “뭐”, “무엇”, “무슨” 등의 다양한 형태로 나타나며, 질문의 종류에 따라 다르게 사용됩니다.
명사의 중요성에 대한 연구
관련 문서: https://www.glossa-journal.org/article/id/5014/
- 연구 결과에 따르면, 한국어의 문맥에서 명사는 질문의 초점이 되는 경향이 있습니다.
- 특히, 명사가 질문에서 생략되면 질문의 의도나 의미를 이해하기 어려워질 수 있습니다. 이는 명사가 질문의 정확성과 명료성을 유지하는 데 중요한 역할을 한다는 것을 나타냅니다.
언어 처리에서 명사의 중요성
관련 문서: https://link.springer.com/chapter/10.1007/978-3-030-90761-7_8
- 명사는 문장 구조와 의미 해석에서 중요한 역할을 합니다.
- 한국어와 같은 언어에서는 명사가 문장의 주제나 객체를 나타내며, 질문의 초점을 맞추는 데 필수적입니다. 이는 언어 처리 및 이해에서 명사의 역할을 강조합니다 .
이를 해결하기 위해서 Open-source Korean Text Processor / 오픈소스 한국어 처리기를 사용할 것입니다.
https://github.com/open-korean-text/open-korean-text/tree/master
GitHub - open-korean-text/open-korean-text: Open Korean Text Processor - An Open-source Korean Text Processor
Open Korean Text Processor - An Open-source Korean Text Processor - open-korean-text/open-korean-text
github.com
질문을 정규화 및 어구를 추출합니다.

이를 프로세스로 정리하면 다음과 같습니다.

이처럼 질문에서 명사를 추출해서 각 텍스트의 유사도를 확인하고자 합니다.
🔎 텍스트 유사도 분석 알고리즘
결론적으로 사용한 임베딩과 메트릭은 다음과 같습니다.
TF-IDF + Cosine Similarity
임베딩: TF-IDF로 문서의 단어들을 벡터로 변환합니다
메트릭: 코사인 유사도를 사용하여 두 문서의 유사성을 계산합니다.
📍 임베딩(Embedding)
임베딩은 텍스트 데이터를 수치 벡터로 변환하여 기계 학습 알고리즘이 쉽게 처리할 수 있도록 하는 방법입니다.
즉, 유사도를 메트릭에 넣어 계산하기 전 텍스트 임베딩이라고 하는 단어 또는 문장에 해당하는 특징을 인코딩한 수십에서 수천 차원을 가지는 벡터를 생성하는 과정입니다.
임베딩 종류
- TF-IDF
- Word2vec
- Doc2vec
- ELMo
- BERT
임베딩에는 여러 방식이 있지만, 이 중에서 저는 TF-IDF 방식을 사용하고자 했습니다.
그 이유는 다음과 같습니다.
- 질문을 명사의 형태로 추출하여 유사도를 비교하게 됩니다.
- 각 단어의 중요도를 평가하여 문서의 특성을 잘 반영하는 벡터를 만들기 좋다는 판단이 들었습니다.
- 예를 들면,
수시,정시,재외국민등의 단어는 질문마다 존재하기 때문에 중요도가 반영됩니다.
- 많은 메모리를 필요로하지 않고, 매우 빠릅니다.
- 챗봇의 특성상 같은 질문인지 판단하는데 많은 시간을 소요할 경우 사용자들의 이탈률이 증가할 것이고, 서비스의 실패로 이어질 수 있습니다.
- 구현이 쉽습니다.
- 아파치에는 이전 글에서도 언급했었던 Elasticsearch의 기반이 되는 Lucene이라는 정보 검색 라이브러리가 있다.
- 이를 이용해서 TF-IDF를 가중치를 직접 조절하면서 원하는 결과를 텍스트 임베딩을 적용할 수 있습니다.
- GPU가 필요 없습니다.
- GPU는 클라우스 서버로 감당하기에 비싼 비용을 가지고 있고 서비스에서 이미 Data Server에 GPU가 많이 할당되어 있어 매 질문마다 GPU를 사용하게 되면 Data Server에 부담이 갈 수 있습니다.
- 만약 성능이 생각만큼 나오지 않는다면 즐거운 마음으로 고도화 글을 작성해보겠습니다!
- TF-IDF 특성상 문장 벡터의 가중치가 음의 값이 되는 것이 불가능하므로 두 문서 사이의 코사인 유사도는 0(독립)에서 1(일치)까지의 값으로 표현됩니다.
- 성분 규제 유사도가 -1인 경우, 즉 완전히 반대인 경우까지 고려할 필요가 없습니다.
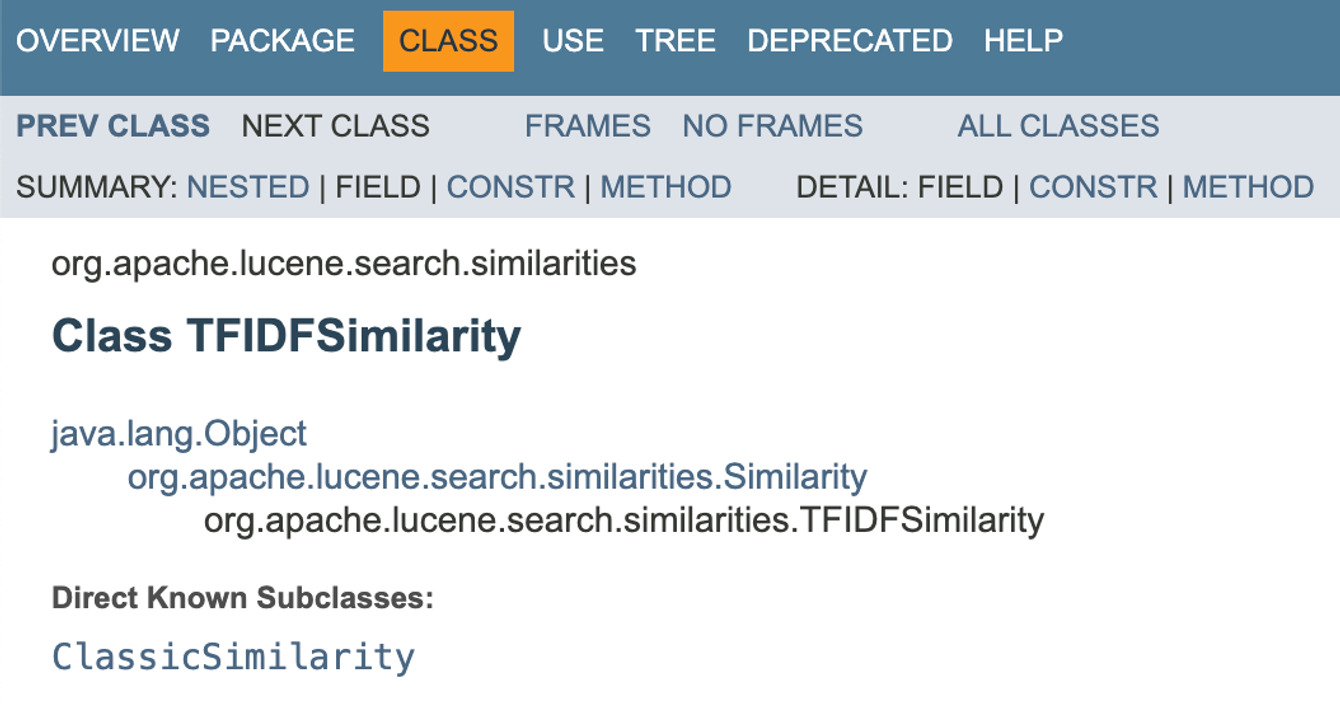
⚙️ Apache Lucene의 TFIDFSimilarity 가중치 설정
가중치의 의미를 자세히 알고 싶다면 아래의 링크를 참고해주세요!
TF-IDF(Term Frequency-Inverse Document Frequency)
- coord(int overlap, int maxOverlap):
- 기능: 쿼리 용어의 겹침 비율에 기반한 점수 요인 계산.
- 개선: 현재 구현은 고정값 1.0을 반환하지만, 겹침 비율에 따라 가변적인 값을 반환하도록 수정할 수 있습니다.
- 예를 들어, overlap / (float) maxOverlap을 반환하여 더 많은 겹침이 있는 경우 더 높은 점수를 부여할 수 있습니다.
- queryNorm(float sumOfSquaredWeights):
- 기능: 쿼리 가중치의 정규화 값을 계산.
- 개선: 현재 구현은 고정값 1.0을 반환하지만, 기본 구현대로 1 / Math.sqrt(sumOfSquaredWeights)를 사용하여 쿼리 가중치를 정규화할 수 있습니다.
- tf(float freq):
- 기능: 문서 내 용어 빈도에 기반한 점수 요인 계산.
- 개선: 현재 제곱근을 사용하고 있지만, 필요에 따라 다른 함수를 사용할 수 있습니다.
- 예를 들어, 로그 스케일을 사용하여 1 + Math.log(freq)와 같은 형태로 변경할 수 있습니다.
- idf(long docFreq, long docCount):
- 기능: 역문서 빈도(IDF) 계산.
- 개선: 기본 구현을 사용하여 Math.log((docCount + 1) / (double) (docFreq + 1)) + 1.0을 유지할 수 있습니다.
- lengthNorm(FieldInvertState state):
- 기능: 문서 길이에 기반한 정규화 값 계산.
- 개선: 기본적으로 1.0을 반환하지만, 문서 길이에 따라 가변적인 값을 반환하도록 수정할 수 있습니다.
- 예를 들어, 1 / (float) Math.sqrt(state.getLength())와 같이 길이가 길수록 낮은 값을 반환하도록 할 수 있습니다.
- 기타 메서드 개선:
- sloppyFreq(int distance): 거리 기반의 부정확한 일치 빈도 계산.
- scorePayload(int doc, int start, int end, BytesRef payload): 페이로드 데이터를 기반으로 점수 요인 계산.
- decodeNormValue(long norm) 및 encodeNormValue(float f)
- 인코딩 및 디코딩 함수는 현재 고정값을 반환하고 있지만, 실제 길이 정보를 기반으로 적절한 인코딩 및 디코딩을 구현할 수 있습니다.
📍 메트릭(Metric)
텍스트의 유사도는 벡터 차원이 데이터 객체의 특징을 나타내는 두 벡터 사이의 거리입니다.
간단히 말해서 유사도는 두 데이터 객체가 얼마나 비슷하거나 다른지를 측정한 것입니다.
일반적으로 0~1의 범위를 측정하며, 두 벡터 간의 거리가 작다면 객체 간 유사도가 높다고 하고 반대의 경우 유사도가 낮다고 합니다.
메트릭의 종류에는 여러가지가 있지만
- CosineSimilarity
- IntersectionSimilarity
- JaccardSimilarity
- JaroWinklerSimilarity
- LevenshteinDistance
- LongestCommonSubsequenceDistance
2가지를 중점으로 정리해보겠습니다.
- 유클리드 거리
- 벡터 간의 직선 거리를 계산하여 두 텍스트 간의 차이를 정량화합니다.
- 코사인 유사도
- 두 벡터 간의 각도를 계산하여 유사도를 측정합니다.
- 이는 벡터 크기보다는 방향에 집중하므로, 문장의 길이가 다르더라도 유사도를 정확히 계산할 수 있습니다.
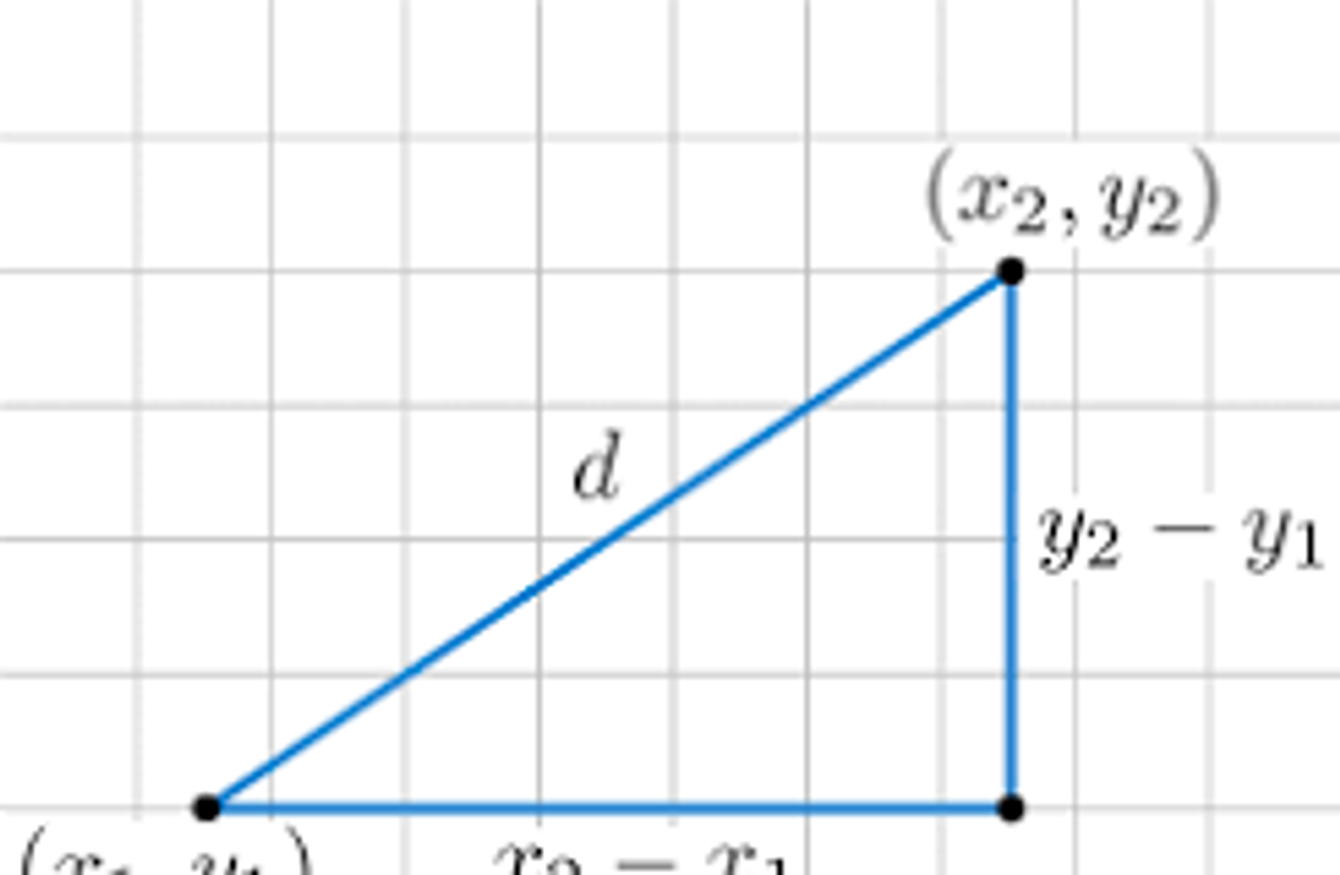
유클리드 거리
유클리드 거리는 익숙한 피타고라스 정리를 사용하여 두 점 사이의 거리를 계산합니다.
거리가 멀다면 두 벡터의 유사도가 낮다고 이해할 수 있습니다.
Cosine Similarity
코사인 유사도는 두 벡터 사이 각도의 코사인으로 두 벡터의 유사성을 계산합니다.
내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도를 의미합니다.
각도가 0°일 때의 코사인값은 1이며, 다른 모든 각도의 코사인값은 1보다 작습니다.
따라서 이 값은 벡터의 크기가 아닌 방향의 유사도를 판단하는 목적으로 사용되며, 두 벡터의 방향이 완전히 같을 경우 1, 90°의 각을 이룰 경우 0, 180°로 완전히 반대 방향인 경우 -1의 값을 갖습니다.
이 때 벡터의 크기는 값에 아무런 영향을 미치지 않으며, 코사인 유사도는 특히 결과값이 [0,1]의 범위로 떨어지는 수 공간에서 사용됩니다.
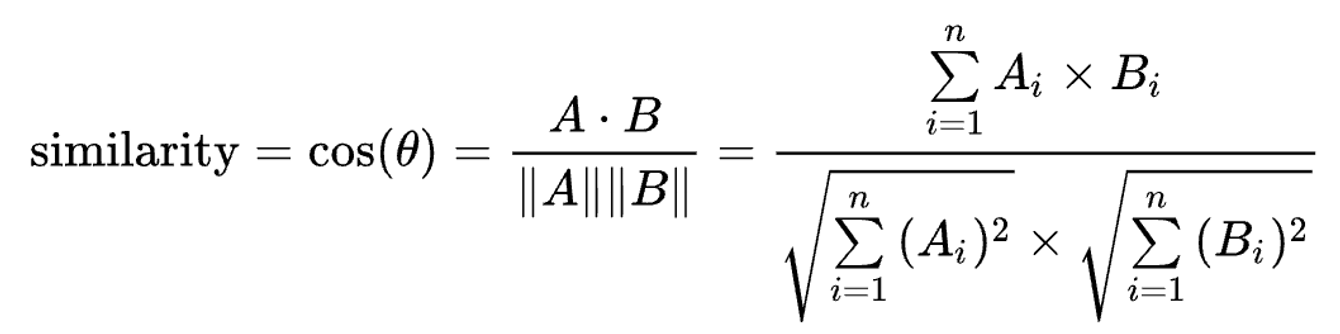
해당 식이 텍스트 매칭에 적용될 경우, A, B의 벡터로는 일반적으로 해당 문서에서의 단어 빈도가 사용됩니다.
코사인 유사도는 문서들간의 유사도를 비교할 때 문서의 길이를 정규화하는 방법의 하나라고 볼 수도 있습니다.
두 가지 방식을 간단하게 비교해보았습니다.
이 중에서 저는 코사인 유사도(Cosine Similarity)를 사용하기로 결정했습니다.
이유는 다음과 같습니다.
- 계산의 효율성
- 벡터 내적과 벡터 크기 계산만으로 유사성을 평가하므로 계산이 비교적 빠르고 간단합니다.
- 직관적으로 해석이 가능합니다.
- 1에 가까울 수록 두 벡터가 유사하다는 것을 의미하므로 이해하기 쉽습니다.
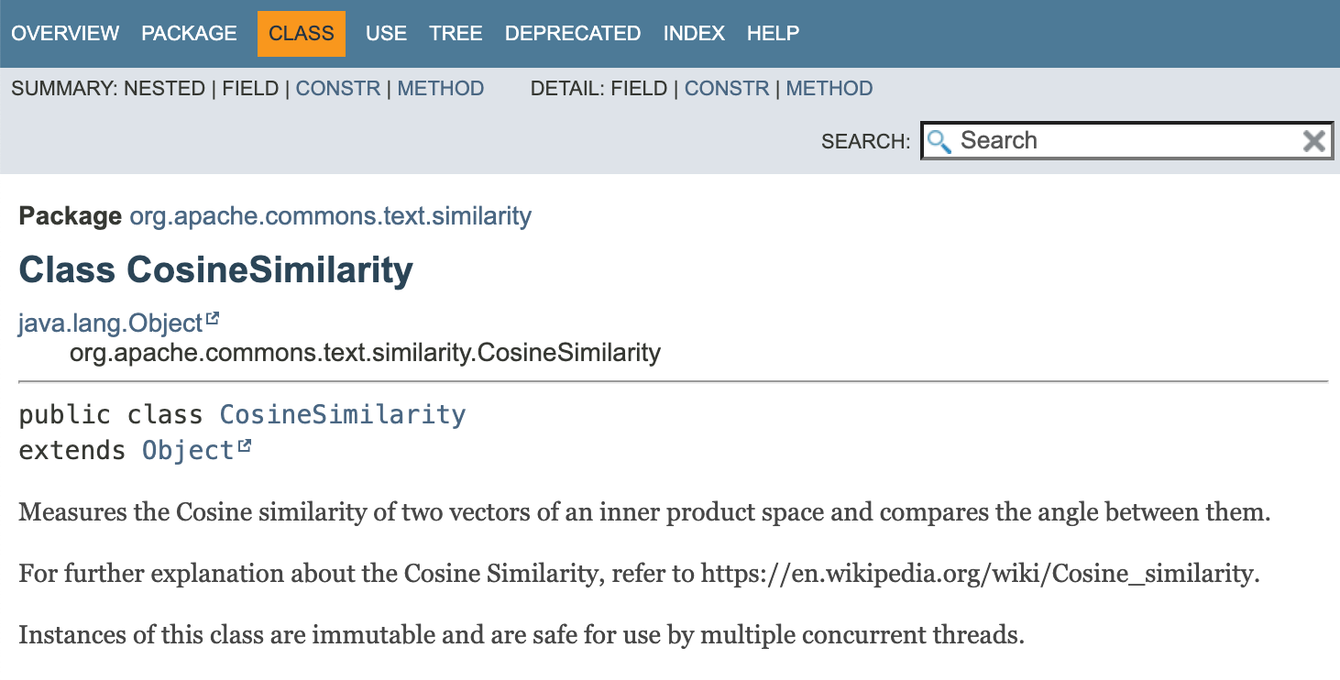
- Apache Lucene TF-IDF의 문서에서 직접 Cosine Similarity를 언급
- 문서 간 비교 가능성 유지를 위해 코사인 유사도는 두 문서 간 유사성을 계산할 수 있게 해줍니다.
- Recall that Cosine Similarity can be used find how similar two documents are.
- https://lucene.apache.org/core/6_6_1/core/org/apache/lucene/search/similarities/TFIDFSimilarity.html
- 구현하기 쉽습니다.
- Apache의 text similarity를 통해 쉽게 구현할 수 있습니다
🌊 전체 흐름 정리
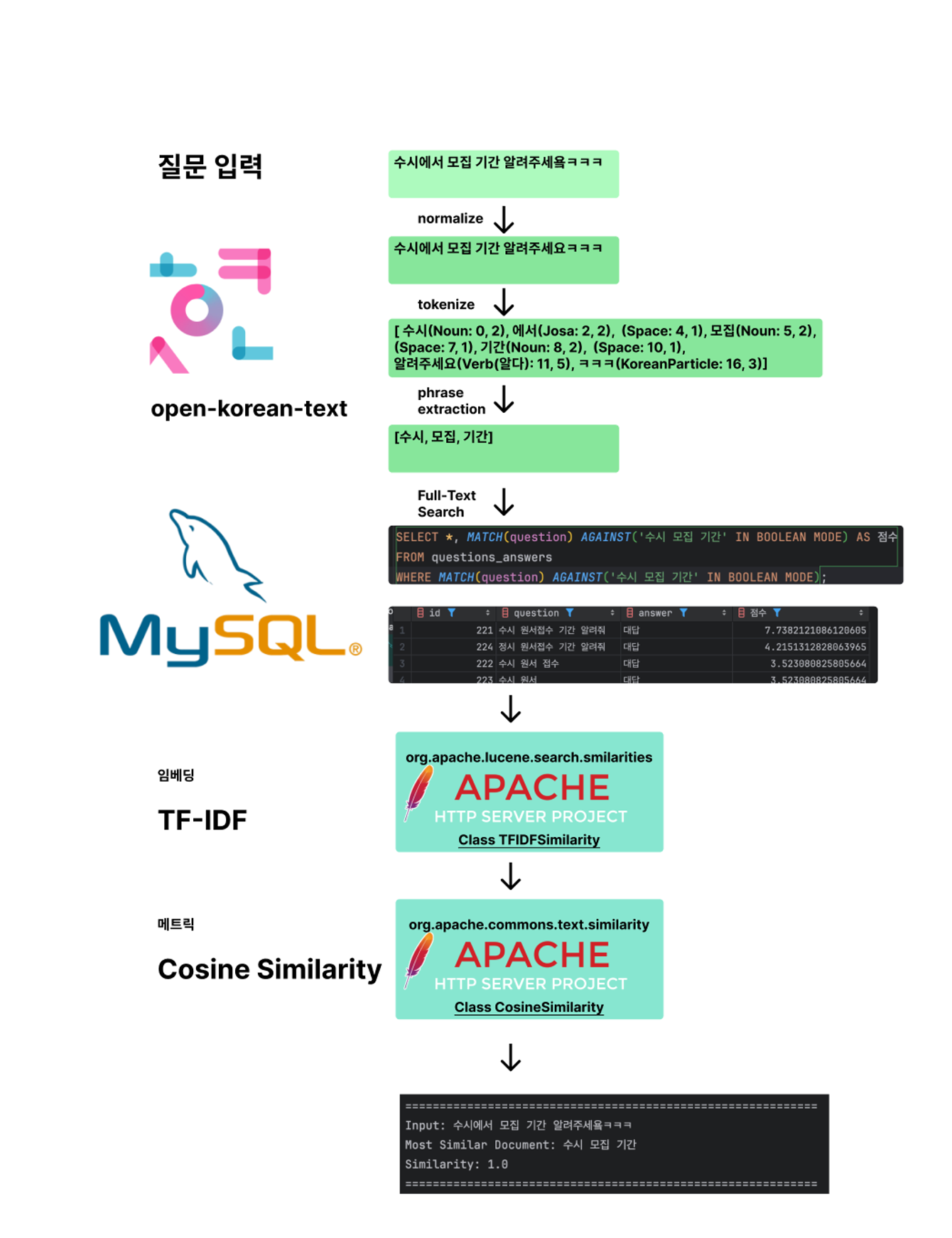
위의 예시로 흐름을 파악해보겠습니다.
- 질문(수시에서 모집 기간 알려주세욬ㅋㅋㅋ) 이 들어옵니다.
- 질문을 명사로 이루어진 형태로 정규화 및 토큰화를 진행합니다.
- 가공된 단어들로 MySQL을 통해 관련된 정보들을 Full-Text Search 합니다.
- 찾아온 DB에 저장되어있던 질문들 중 유사도가 0.95 이상(변경가능성이 충분히 존재합니다)인 질문이 있는지 TF-IDF와 Cosine Similarity를 이용해 검증합니다.
- 0.95 이상인 질문은 유사한 질문이라고 판단하고 해당 답변을 반환합니다.
- 0.95 이상인 질문이 없는 경우에는 Data Server에서 답변을 받아오고(RAG 방식의 LLM 서버) 질문을 저장합니다.
✅ 위 플로우를 간단하게 Test
원래는 가장 유사도가 높은 질문을 찾는 로직이 Test에 들어가면 안 되겠지만 간단한 Test이니 진행해보았습니다.
전체 Test Code
public class TextSimilarityUtilsTest {
private static List<String> documents;
@BeforeAll
public static void setUp() {
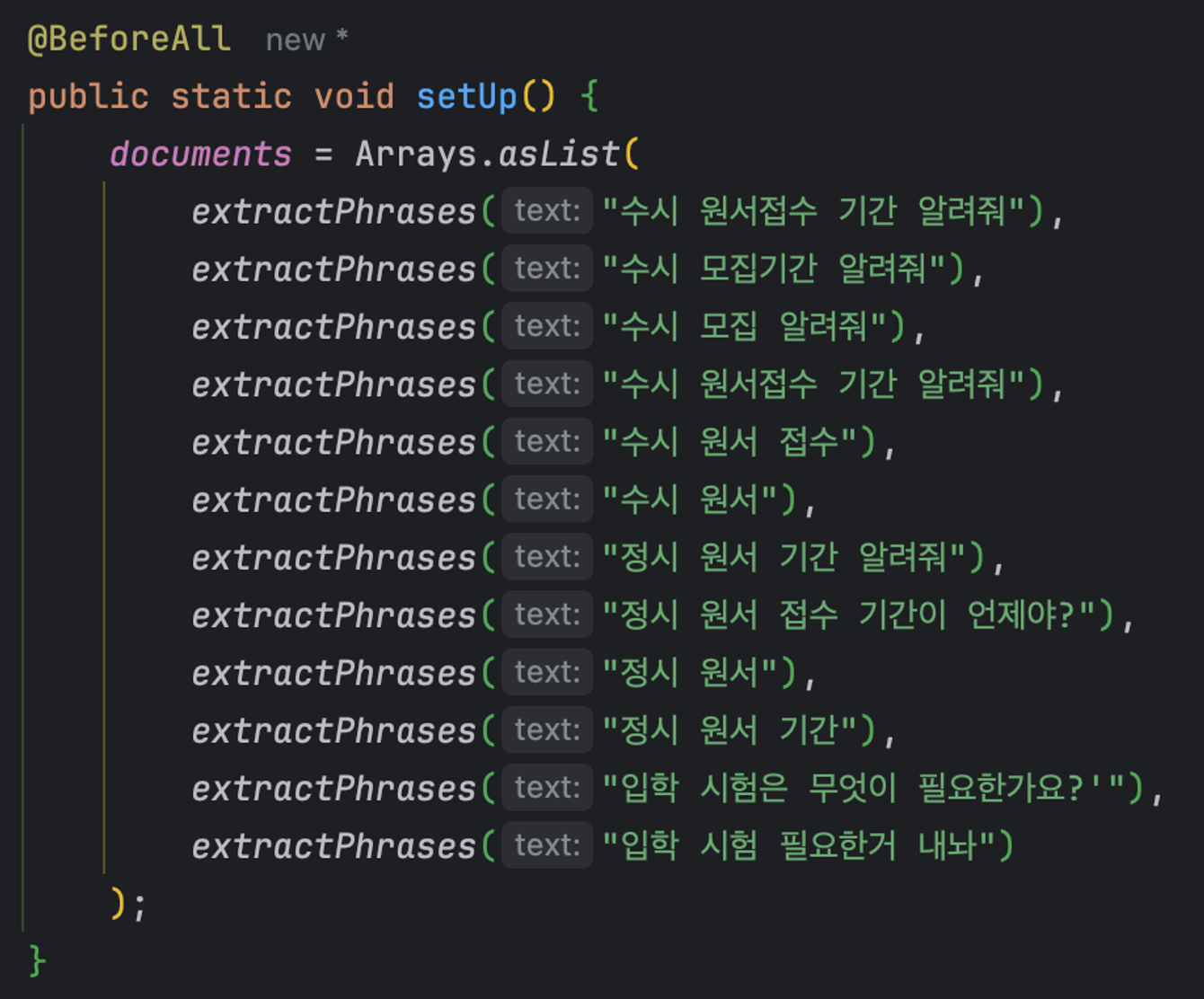
documents = Arrays.asList(
extractPhrases("수시 원서접수 기간 알려줘"),
extractPhrases("수시 모집기간 알려줘"),
extractPhrases("수시 모집 알려줘"),
extractPhrases("수시 원서접수 기간 알려줘"),
extractPhrases("수시 원서 접수"),
extractPhrases("수시 원서"),
extractPhrases("정시 원서 기간 알려줘"),
extractPhrases("정시 원서 접수 기간이 언제야?"),
extractPhrases("정시 원서"),
extractPhrases("정시 원서 기간"),
extractPhrases("입학 시험은 무엇이 필요한가요?'"),
extractPhrases("입학 시험 필요한거 내놔")
);
}
@DisplayName("유사도가 가장 높은 문장 찾기")
@ParameterizedTest(name = "{index} => input={0}")
@MethodSource("inputQuestions")
public void 유사도가_가장_높은_문장_찾기(String input, boolean expectedBoolean) throws Exception {
String inputPhrases = extractPhrases(input);
double maxSimilarity = -1;
String mostSimilarDocument = null;
for (String document : documents) {
Map<CharSequence, Integer> tfIdf1 = TextSimilarityUtils.computeTfIdf(documents, inputPhrases);
Map<CharSequence, Integer> tfIdf2 = TextSimilarityUtils.computeTfIdf(documents, document);
double similarity = TextSimilarityUtils.computeCosineSimilarity(tfIdf1, tfIdf2);
if (similarity > maxSimilarity) {
maxSimilarity = similarity;
mostSimilarDocument = document;
}
}
System.out.println("============================================================");
System.out.println("Input: " + input);
System.out.println("Most Similar Document: " + mostSimilarDocument);
System.out.println("Similarity: " + maxSimilarity);
System.out.println("============================================================\n");
assertNotNull(mostSimilarDocument, "There should be a most similar document.");
assertThat(expectedBoolean).isEqualTo(maxSimilarity >= 0.95);
}
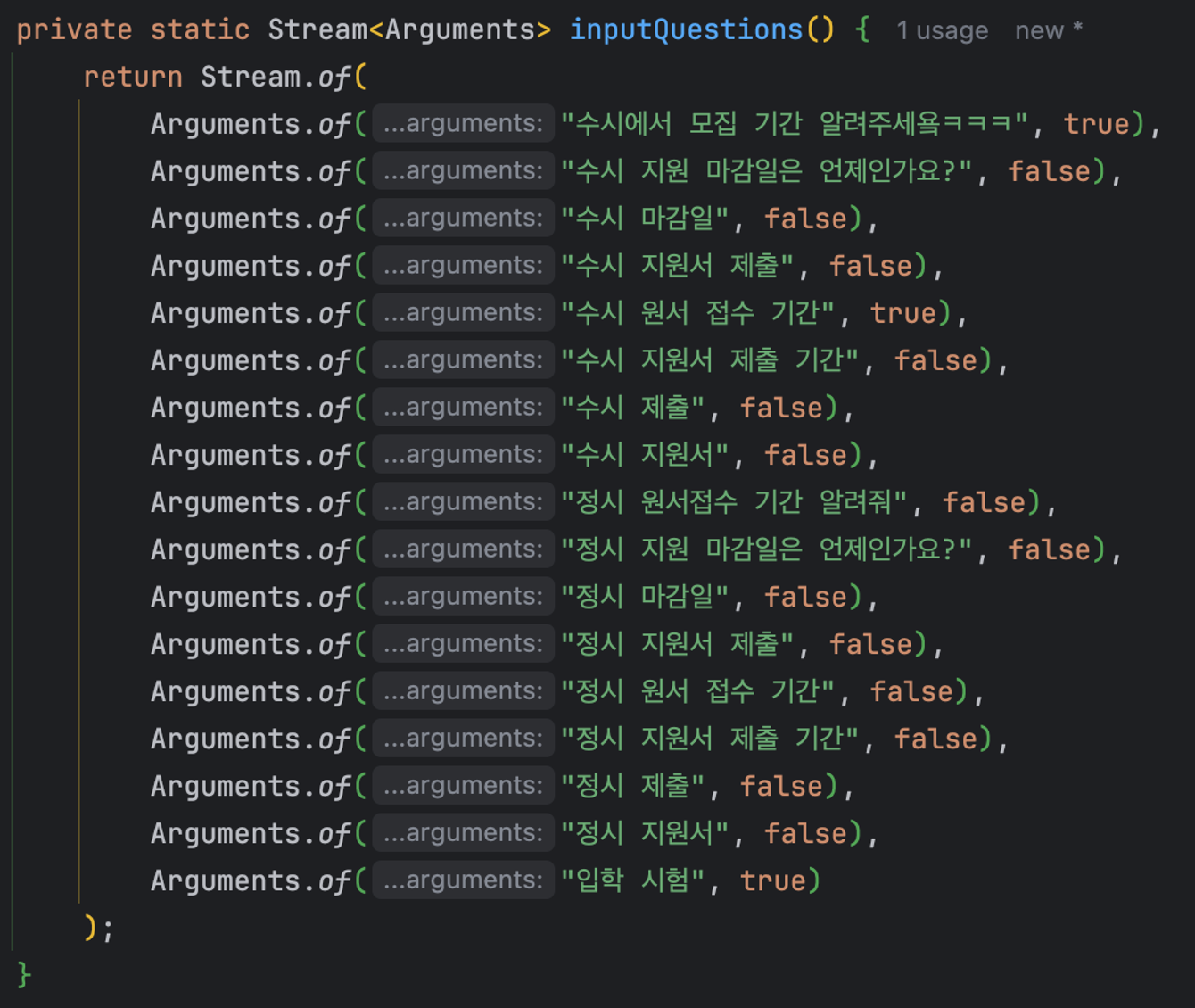
private static Stream<Arguments> inputQuestions() {
return Stream.of(
Arguments.of("수시에서 모집 기간 알려주세욬ㅋㅋㅋ", true),
Arguments.of("수시 지원 마감일은 언제인가요?", false),
Arguments.of("수시 마감일", false),
Arguments.of("수시 지원서 제출", false),
Arguments.of("수시 원서 접수 기간", true),
Arguments.of("수시 지원서 제출 기간", false),
Arguments.of("수시 제출", false),
Arguments.of("수시 지원서", false),
Arguments.of("정시 원서접수 기간 알려줘", false),
Arguments.of("정시 지원 마감일은 언제인가요?", false),
Arguments.of("정시 마감일", false),
Arguments.of("정시 지원서 제출", false),
Arguments.of("정시 원서 접수 기간", false),
Arguments.of("정시 지원서 제출 기간", false),
Arguments.of("정시 제출", false),
Arguments.of("정시 지원서", false),
Arguments.of("입학 시험", true)
);
}
}
MySQL에서 Full-Text Search한 결과를 다음과 같다고 설정했을 때
이 질문들이 어떤 어떤 질문에 얼마만큼의 유사도를 가지는지 Test 해보았습니다.
결과
============================================================
Input: 수시 원서접수 기간 알려줘
Most Similar Document: 수시 원서 접수 기간
Similarity: 0.9999999999999998
============================================================
============================================================
Input: 수시 지원 마감일은 언제인가요?
Most Similar Document: 수시 원서
Similarity: 0.11624763874381928
============================================================
============================================================
Input: 수시 마감일
Most Similar Document: 수시 원서
Similarity: 0.16222142113076252
============================================================
============================================================
Input: 수시 지원서 제출
Most Similar Document: 수시 원서
Similarity: 0.16222142113076252
============================================================
============================================================
Input: 수시 원서 접수 기간
Most Similar Document: 수시 원서 접수 기간
Similarity: 0.9999999999999998
============================================================
============================================================
Input: 수시 지원서 제출 기간
Most Similar Document: 정시 원서 기간
Similarity: 0.3405026123034995
============================================================
============================================================
Input: 수시 제출
Most Similar Document: 수시 원서
Similarity: 0.22360679774997896
============================================================
============================================================
Input: 수시 지원서
Most Similar Document: 수시 원서
Similarity: 0.22360679774997896
============================================================
============================================================
Input: 정시 원서접수 기간 알려줘
Most Similar Document: 수시 원서 접수 기간
Similarity: 0.8999999999999998
============================================================
============================================================
Input: 정시 지원 마감일은 언제인가요?
Most Similar Document: 정시 원서
Similarity: 0.11624763874381928
============================================================
============================================================
Input: 정시 마감일
Most Similar Document: 정시 원서
Similarity: 0.16222142113076252
============================================================
============================================================
Input: 정시 지원서 제출
Most Similar Document: 정시 원서
Similarity: 0.16222142113076252
============================================================
============================================================
Input: 정시 원서 접수 기간
Most Similar Document: 수시 원서 접수 기간
Similarity: 0.8999999999999998
============================================================
============================================================
Input: 정시 지원서 제출 기간
Most Similar Document: 정시 원서 기간
Similarity: 0.42562826537937437
============================================================
============================================================
Input: 정시 제출
Most Similar Document: 정시 원서
Similarity: 0.22360679774997896
============================================================
============================================================
Input: 정시 지원서
Most Similar Document: 정시 원서
Similarity: 0.22360679774997896
============================================================
Process finished with exit code 0
Test 결과 프로덕트 코드에서는 MySQL에서 Full-Text Search로 찾아온 질문 list가 어떻게 구성되는지가 성능에 크게 좌우할 것으로 예상되고, Boolean Mode의 옵션을 sql을 실행하기 전에 추가하여 query를 생성한다면 좀더 좋은 성능과 정확성을 갖출 수 있을 것이라는 생각이 들었습니다.
아직 가중치를 조절할 여부도 많고, 미흡한 부분이 보입니다.
그러나 질문이 완전히 일치하지 판단하는 경우에는 지장이 없다고 판단이 들었습니다.
🥑 마무리
해당 글은 프로젝트의 기능을 구상하는 단계에서 작성했습니다.
텍스트 유사도를 검사해야하는 상황에서 어떤 방식이 나을지 고민하고 계획하는 단계를 블로그로 작성해보았는데, 앞으로도 새로운 고민거리가 생긴다면 이런식으로 정리해보는 습관을 들여야겠다는 생각이 들었습니다 (재밌네요ㅎ)
아직 미흡한 부분이 많을 것이고 분명 문제가 발생하겠지만, 그것 역시 잘 정리해서 공유해보도록 하겠습니다.
📒 Reference
- https://github.com/goonbamm/korean_apparent_similarity
- https://medium.com/cdri/머신러닝-모델로-성분-규제-데이터-의미있게-활용하기-be56461eab2c
- https://lucene.apache.org/core/6_6_1/core/org/apache/lucene/search/similarities/TFIDFSimilarity.html
- https://commons.apache.org/proper/commons-text/apidocs/org/apache/commons/text/similarity/CosineSimilarity.html
- https://github.com/open-korean-text/open-korean-text/tree/master
- https://www.essential2189.dev/db-performance-fts#333c79ce-c182-4c2a-8f01-50197dfed596
- https://dev.mysql.com/
- https://velog.io/@dy6578ekdbs/NLP-문장-유사도-측정-개인정보-검출#자연어-처리란
'프로젝트 삽질 🧯' 카테고리의 다른 글
| 프로젝트 & DB | 텍스트 유사도 검색 어떻게 구현할까?(1) - Elasticsearch를 안 쓴 이유와 MySQL Full Text Index (0) | 2024.07.07 |
|---|---|
| 프로젝트 | redis 적용 및 최적화 도전기 (2) | 2024.06.19 |
| 프로젝트 | Artillery 부하 테스트 (1) | 2024.05.25 |


